中国製コピー商品でも良いのですか?
暫く混乱が続くのは避けられない可能性大
先週、日米両株式市場を混乱の坩堝に突き落としたのは中国の「ヘッジファンド」だった。彼らはまんまと仕掛けに成功した。米中対立の構図の中で、その米国株式市場を大きな混乱に陥れた上に、日本円換算では兆円単位の収益を挙げた。だから、きっと笑いが止まらないだろう。それも中国のお家芸である「コピー商品」による仕業だから尚更だ。正に「一矢報いた」と祝杯を挙げている筈だ。
一言で先週起きた「DeepSeek問題」への私の捉え方を説明すれば、こういうことになる。勿論、何の確たる証拠もないが、状況証拠を繋ぎ合わせて、当然、技術的な背景や先週発表になった大手テクノロジー企業(マイクロソフト、META、IBM、アップルなど)の決算動向やその後のカンファレンスでの内容を踏まえた上で、また金融業界というドロドロした世界の裏側(言い換えると自己中心的強欲の塊)も考えれば、こう考えるのが最も妥当だと思う。正直、「DeepSeek」の創業者がヘッジファンドだと聞いた時、素直に「またか」と思った。そんな「DeepSeek問題」に振り回された、日米株式市場の先週の騰落率は下記の通り。NASDAQの週間騰落率と年初来騰落率が一見すると一緒だが、より小数点以下桁数を増やせば、週間騰落率が△1.6380%で、年初来騰落率が△1.6398%なので、計算間違いでは無い。更に付け加えると、フィラデルフィア半導体指数ことSOX指数の週間騰落率は△6.10%と抜きんでて悪いことがわかる。これらが「DeepSeek問題」の影響であり、恐らく、もう暫くはこの混乱は収まらないだろう。ただそうなったとしても、狼狽する必要は何処にもない。

今号は冒頭で結論を言ってしまえば、これは大きな技術革新を伴うAI革命の序章に、起こるべくして起きた「石のふるい落とし」のひとつに過ぎないということ。何故なら、大きな技術革新と、それに伴う成長過程では、何度も既成概念が覆される瞬間を乗り越えることになるからだ。成長痛のひとつだと思って良い。積極的に新しい知識を取り入れることを怠り、常に知識をアップデート・最適化することを忘れ、漫然と今までの既存の知識と経験則の延長線上で物事を捉える(どうしても人間誰しもこうなるのは当然なのだが)努力を続けずにいても、濡れ手に粟のように高い投資収益が転がり込むことほど甘くはない。市場の神様はそこまで優しくはないのだ。ただ反対に、きちんと努力続けていれば、この局面が何を意味しているかは確りと見えていると思う。
短期的に上がった下がったで一喜一憂しても仕方が無いのが投資の世界だ。右肩上がりで上がり続けることなど決してない。見出しで「中国製コピー商品でも良いのですか?」と敢えて揶揄して表現してみたが、たとえて言えば、本物と見紛う程に良く出来たROLEXだが、秒針が1秒毎に動く(自動巻きでは無いという意味)バッタ物があった。でも、”時計”という効用としては充分使える、中には防水性能がより優れているものなどもある。ならば、それでROLEXよりも満足されますかということと一緒だということ。それが「DeepSeek問題」の本質だと考える。ただ今現在、市場関係者のみならず、報道やネット上のSNSなどの情報も、結論に辿り着かずに混乱が甚だしいままだ。恐らく今週はトランプ大統領とエヌビディアのジャンセンCEOがホワイトハウスで面談した際の話の内容の消化などに時間が掛かるだろう。関税や輸出規制の話が錯綜しそうだ。
FOMCでの利下げは見送り
先週28日~29日には米国の日銀金融政策決定会合にあたるFOMCが行われた。そして利下げの見送りが発表されたが、結果が市場の予想通りだったこともあり、DeepSeek問題の陰に完全に隠れて、市場で話題になることもミニマムだったと言える。ただFOMCで今年2025年に何回利下げがあるかという見立てに関しては、まだまだ市場内で一本化されていないのも事実だ。
12月のFOMCで発表されたドット・チャートが示している利下げ回数は0.25%の利下げが2回。だが不思議と今年も昨年同様、ドット・チャートが示している内容よりも、より回数多く利下げがあるという前提に立つ人が多いのは事実だ。ただアメリカの現在の景況感とインフレ動向を見ていると、この週末の雇用統計の結果にもよるが、年内にあと1回の利下げがあるかないかと見るのが妥当だと思われる。ならば何がその判断の違いを生んでいるかと言えば、現状のFFレートの誘導目標と10年債利回りなどの絶対値を「高い」とするスタンスか、「決して高いとは言えない」と見立てているかの違いだろう。
下のチャートは私が市場業務に関わるようになって以降の米国長期金利の推移と、それに重ねてFFレートの誘導目標(黒い線)状況を見ているチャートだ。チャートの右側約1/3が2008年のリーマン・ショック後のゼロ金利政策以降を示しているが、明らかにそれ以前と、その後では随分と米国金利の期間構造の建付けも違っている。要は、2008年のリーマン・ショック後で見れば、金利は全て「10数年振りの既にかなり高い」水準にまで上昇しているかに見える。だが一方で、リーマン・ショック前という話で考えると、決して現状の金利水準の絶対値が特別に高いとは思えない。ドットコムバブル後に一旦は金利低下したが、2007年前後は明らかに元に戻り、FFレートの誘導目標でさえ優に5%を超えている。つまり今から16、17年前に遡った2008年のリーマン・ショック、それ以降の金利体系を原体験として刷り込まれた20歳代、30歳代の人達から見れば、今は明らかに金利が高いのだ。仮にドットコムバブル崩壊後の数年を経験値として持っている40歳代を加えても、経験値的には圧倒的に今より低金利の時代の方が長いことがわかる。原体験によって「常識的に考えて・・・」というような時の尺度が違ってくるということには注意が必要だ。
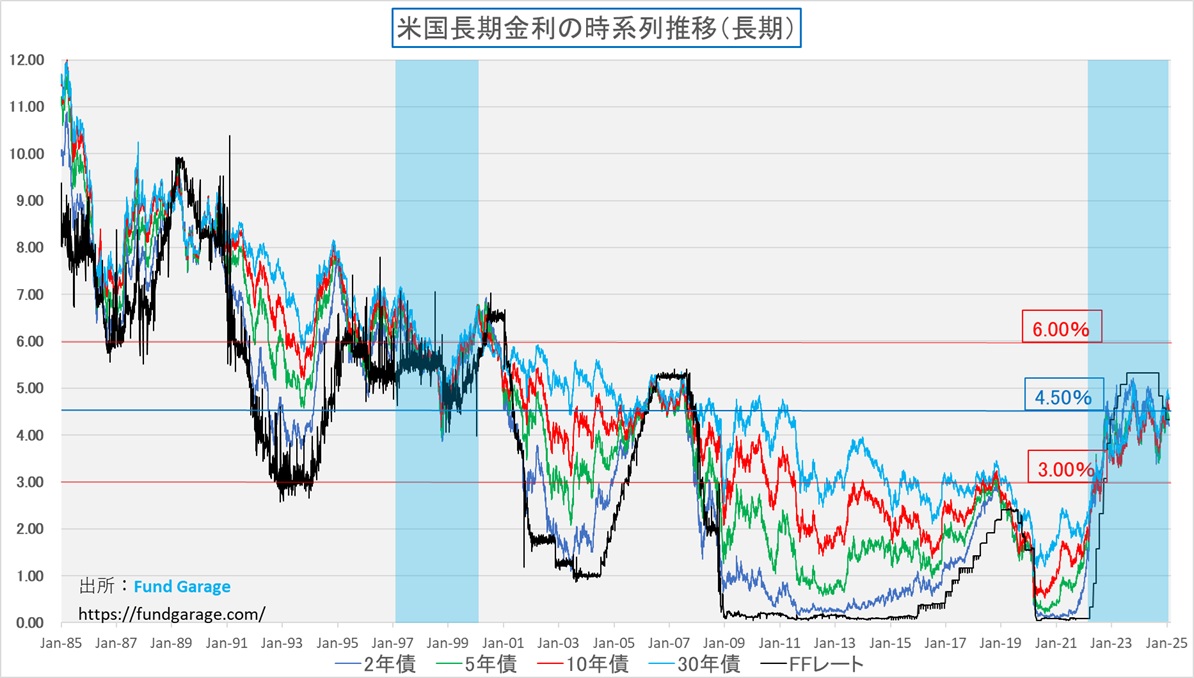
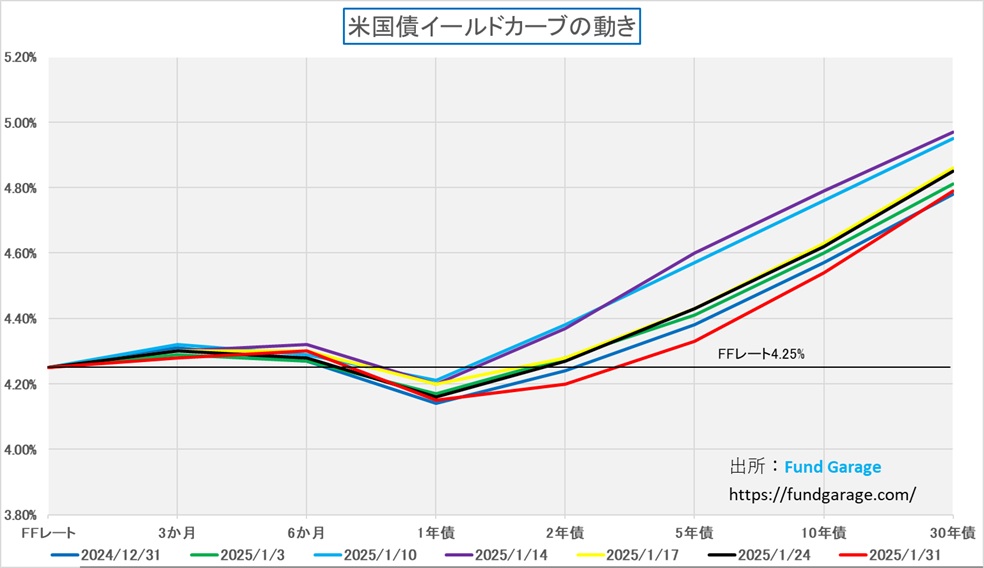
続いて見ておきたいのが、イールドカーブだ。赤い線で描いたのが先週末1月31日のイールドカーブだが、1年物が4.15%と一番低いところにあり、30年債の利回りの4.79%が一番高い。もしFFレートの誘導目標を0.25%の利下げ後の4.00%と仮定し、他の1年未満の金利も揃えるように補正することをイメージすると、イールドカーブはとてもきれいな順イールドにはなる。ただ、注意して貰いたいのは、Y軸のスケール。順イールドに見え易いように、Y軸の目盛りの振り方は最高値がかなり小さくしてある。実際一番上で5.20%なのだから。週末の10年債利回りは4.54%に過ぎないので、実際には絵で見るほどにはイールドカーブは立っておらず、フラットな状況に近い。ただ実際にこの先、トランプ大統領の「MAGA(Make America Great Again」政策が進むのであれば、間違いなく米国経済は強くなる。つまりイールドカーブはより立つ(スティープ化する)だろう。上のチャートを見て貰えば確かだが、通常、FFレートの誘導目標と10年債利回り、30年債利回りのスプレッドは2-3%の開きがあるのがヒストリカルな実績だ。だとすれば、年内0.25%の利下げが1度行われてFFレートの誘導目標が4%になったとしても、更に2度目が行われて3.75%にまで低下したとしても、長期金利が6%や7%近くなっても、おかしくは無いということがわかる。イールドカーブがどの位「スティープ」になるかは、その時々の景気実態を反映する以上、もし「アメリカの黄金時代」が再現されるなら、それなりに「スティープ」になってもおかしくないということだ。
エヌビディアはそもそもボラタイルな銘柄
「King of AI」などと呼ばれることもあるエヌビディア(NVDA)だが、その株価運びはイメージされている以上にボラタイルだ。つまり「荒い」という意味。下のチャートは昨年2024年初めからのNASDAQとマグニフィセント7の株価運びを相対比較したものだが、絶対的なパフォーマンスがずば抜けていることも事実だが、その上下変動がかなり大きいことがわかる。マグニフィセント7のエヌビディア以外の銘柄を見ると、このところはメタプラットフォームズ(META)やアマゾンドットコム(AMZN)が緩やかに下値を切り上げているのも見て取れるが、アップダウンは穏やかだ。
さてに意外なことかも知れないが、NASDAQに対して、アップル(AAPL)とマイクロソフト(MSFT)はアンダーパフォームなのだ。現在時価総額最大企業であるアップル、すなわち時価総額加重平均で計算されるS&P500の中でも、NASDAQの中でも、最も影響力が大きい銘柄はNASDAQに対してアンダーパフォーム、すなわち足を引っ張っている存在だ。因みに第2位はマイクロソフトソフトなので、大型株が市場を牽引しているという単純な解説は的を射ていないのだ。アマゾンドットコムは時価総額第4位、メタプラットフォームズは第6位になる。
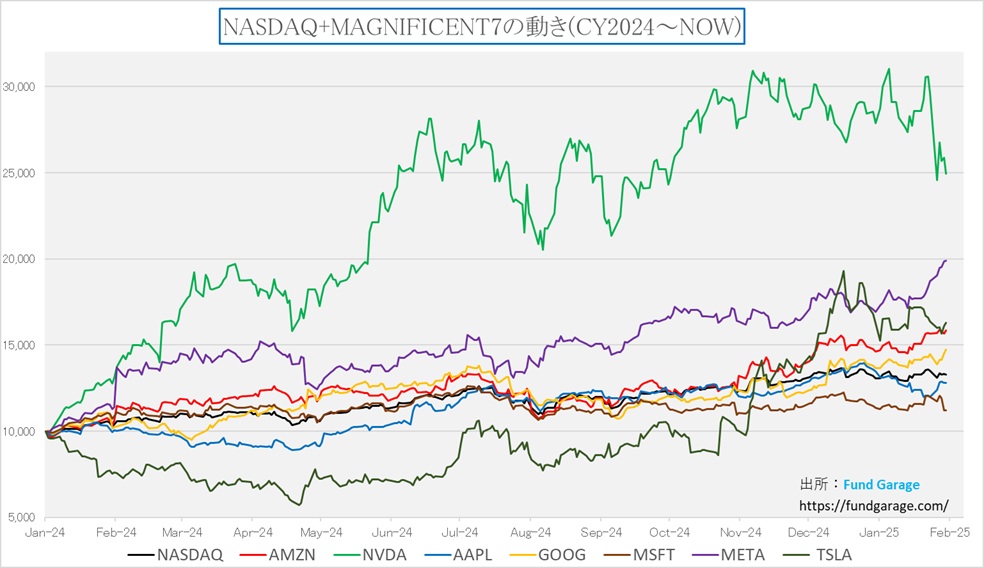
結局、2024年の米国株式市場を牽引したのは、そのセンチメント部分を含めてエヌビディア(NVDA)によるところが大きいと言えるのだが、緑の線を見るだけで、値動きはかなり荒いことがわかる。直近の高値からの下落率は△18.44%にもなるが、昨年7月10日から8月7日までの下落率で言えば△26.68%にもおよんでいる。つまり1/4以上も株価は値下がりしたことになる。ただ、それでもそこから僅か3カ月となる11月7日までに株価は5割を超えて上昇したことから「急落して突っ込んだ場面は買い増しのチャンス」という”相場勘”が蔓延ったとも言える。
そうした投資家の心理は分からないわけでは無いが、まずは客観的に見て、これだけボラタイルな(上下の変動率が大きい)銘柄であることを覚えておいて欲しい。逆に言えば、ボラタイルな銘柄だからこそ、アップサイドに突き抜ける時に大きな力が出るということでもある。俗な言い方をすれば「ハイリスク・ハイリターン」な銘柄とも言える。ただハイリスクでありながらも、ハイリターンが狙える銘柄と考えられるのは、そのファンダメンタルズが抜群だと考えられているからだ。「King of AI」とも呼ばれる程、このAI革命の牽引役、その主役であることに異論をはさむ人もいないと思うが、恐らく「なぜ『King of AI』と呼ばれるのか」というファンダメンタルズを理解していなければ、このボラティリティの高さは厳しい試練でしか無いだろう。値動きの具合や、巷の評判だけで投資をしているとするなら、誰だって株価の1/4があっという間に吹っ飛んでしまえばゾッとするだろうから。だからこそ、自分でファンダメンタルズが理解出来る銘柄、どんなファンダメンタルズを信じてリスクを背負っているのか分かる銘柄に投資をして欲しいとお伝えしている。かのウォーレン・バフェット氏も「自分が分からないものには投資をしない」と言われているのもそのためだ。
蛇足にはなるが、このプレミアム・レポートの主旨が正にそれ。いきなり「エヌビディアのファンダメンタルズがわかりますか?」と言われても、或いは「Armが何やっているのか会社かわかりますか?」と言われても、答えられる方など早々いるものではない。何故なら、巷にあるリサーチ・レポートの多くは、その本質を語らないからだ。それらの多くは、この先AIに任せれば良いようになるであろう財務諸表分析や、テクニカル分析と称する「チャート論」、或いは一般的な市場の流言飛語の類いの解説を縷々綴っているだけだ。その意味でも、是非、「右肩上がりのビジネス・トレンド」の部分は、テクニカル・タームが多くて難しいと諦めずに、是非ぜひ、頑張って読み込んで頂ければと思う。
DeepSeek問題とは何か?
先週の米国時間の月曜日、突如として市場が認識した(実際には、その週末25日~26日時点でシリコンバレー辺りでは相当な騒ぎになっていたとも報じられているが、その真偽は全く不明)のが、DeepSeekという、中国のAIスタートアップ企業であり、オープンソースの大規模言語モデル(LLM)の開発を専門としているという会社の存在だ。ことの発端は、同社が1月20日にリリースした最新モデルの「DeepSeek-R1」(2024年12月に公開された「DeepSeek-V3」を基盤として開発されたとされる)が、数学、コーディング、推論タスクにおいて、OpenAIのo1(2024年9月に発表)と同等の性能を示しながらも、約600万ドルのコストで開発出来たとされたとも報じられたことだ。これによって「高額なGPUがAI開発には大量に必要だ」というエヌビディアのビジネス神話が崩壊したのではとの懸念が拡がった。これを受けて、エヌビディアの株価は先週一週間で△15.81%も下落した。
もし、DeepSeekが発表している開発コスト約600万ドルということが真実だとしたら、これは確かに大きなAI開発のパラダイム・チェンジとなり得るが、その後、DeepSeekのLLM(大規模言語モデル)の開発には、蒸留という手法が使われており、この分のコストが含まれていないということが明らかになってきている。また、その蒸留という手法、平たく言えば、既に完成しているAIモデルから、肝心な部分(トレーニング済みのデータと、重みをつけたモデルそのもの)を「コピペ(複製)」したものであり、更に、それが「OpenAIのAIモデル」から違法にコピペされたものということも明らかになりつつある(目下、米国側が調査中ながら明らかな証拠が既にあるらしい)ということで、まさに「中国らしいAIモデル開発」という理解が浸透しつつあるが、まだ情報が錯綜して侃々諤々の議論が展開している段階。
蒸留とは、正式には「知識蒸留」と呼ぶが、その方法を整理すると下のような内容となる。言わば、模範となる教師モデルとするものがあって、そこからコピペして生徒モデルをつくる。この方法なら約600万ドルで開発出来たということにも真実味はある。
知識蒸留の仕組み
- 教師モデル(Teacher Model)
- パラメータ数が多く、計算コストの高い大規模なAIモデル(GPT-4など)。
- 高精度な予測や複雑な推論が可能。
- 生徒モデル(Student Model)
- 教師モデルよりもパラメータ数が少なく、計算効率の高い軽量モデル。
- 教師モデルから「学習」することで、同等の性能を発揮できるよう設計される。
- 知識の伝達
- 教師モデルが出力する「ソフトなラベル」(クラス間の確率分布)を利用して、生徒モデルが学習。
- 例えば、教師モデルが画像を分類するとき、「犬:80%、猫:15%、ウサギ:5%」というような確率分布を出力。この微妙な分布情報を生徒モデルが学習することで、単なる「正解/不正解」のラベルでは得られない高度な知識を獲得する。
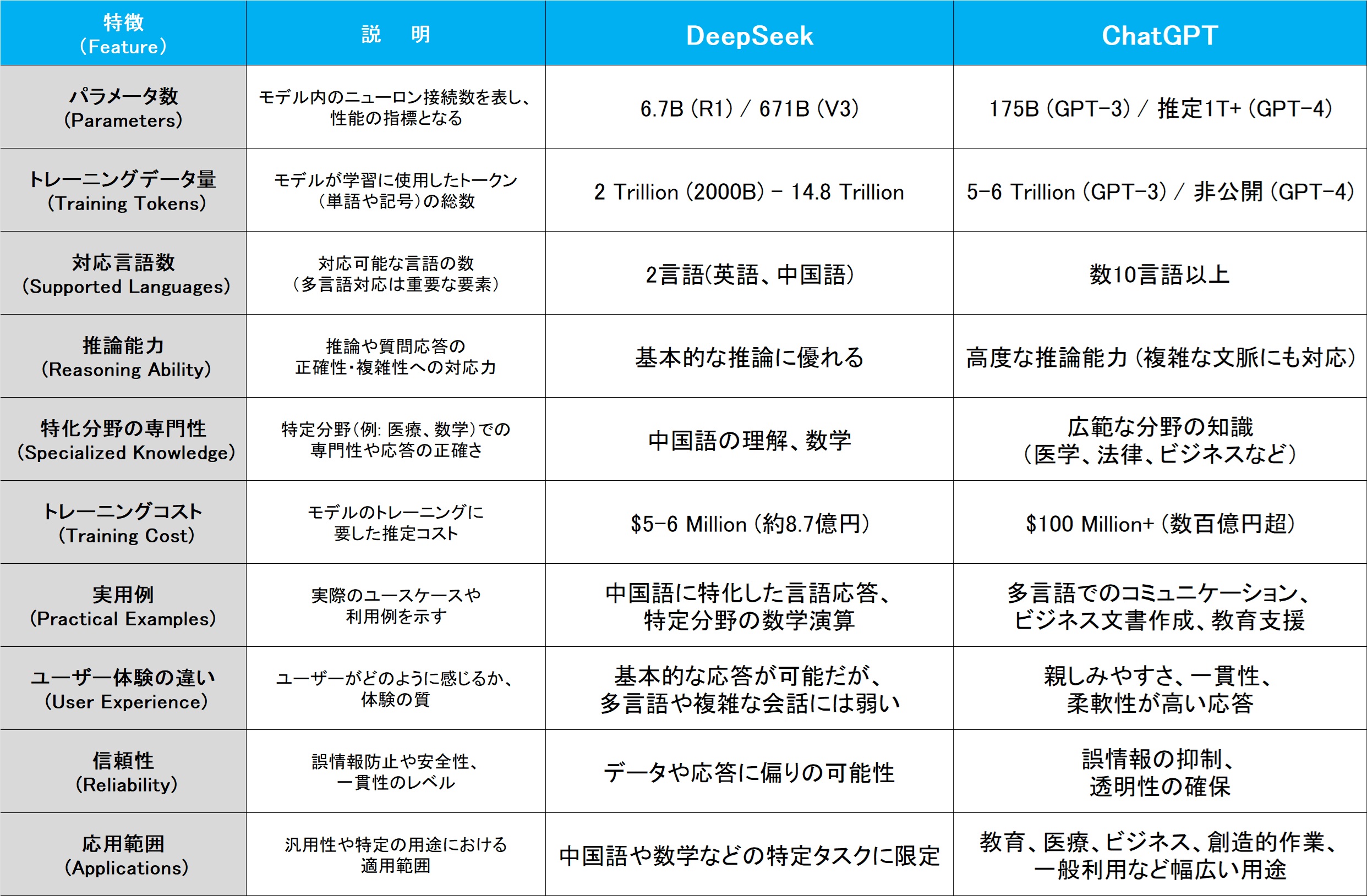
下の表に、公表されている情報は少ないのだが、可能な限り調べてDeepSeekとChatGPTの特徴比較を行った。私が見る限り、結構な差があると思われる。
市場は混乱するもエヌビディアなどは賞賛
不思議なことに、エヌビディアやAI関連の技術を理解している専門家の間では、この蒸留という方法を使って安価なAIモデルを開発したDeepSeekの発表を、寧ろ「AIの裾野を広げること」としてポジティブな評価をしている。実際エヌビディアの広報も「DeepSeek is an excellent AI advancement and a perfect example of Test Time Scaling. Inference requires significant numbers of NVIDIA GPUs and high-performance networking. We now have three scaling laws: pre-training and post-training, which continue, and new test-time scaling.(DeepSeekは、AIの素晴らしい進歩であり、テストタイムスケーリングの完璧な例です。推論には、膨大な数のエヌビディア製GPUと高性能ネットワーキングが必要です。我々は現在、3つのスケーリング法則を持っています。それは、継続的なプレトレーニングとポストトレーニング、そして新しいテストタイムスケーリングです)」というコメントを発表している。
また大規模言語モデルのClaude AIを開発するAnthropic(アンソロピック)の共同創設者でありCEOを務めているダリオ・アモディ氏(OpenAIの元研究担当副社長)も、自身のブログの中でDeepSeekのことを語っている。その要点を整理するとこんな感じになる。
- Scaling Lawの支配的な影響は継続
- DeepSeekの成果は驚異ではなく、トレンドの範囲
- Nvidiaへの影響は限定的であり、長期的にはプラス
- 米中のAI覇権争いは2026-2027年に決定的局面を迎える
- 輸出規制はむしろ強化すべき
ということで、理解すべきは「Scaling Law」ということになる。おそらく、この点を理解しておかないとDeepSeek問題の勘所を見誤ると思われるが、実はこの「Scaling Law」に関しては、年初のCES2025の基調講演で、既にエヌビディアのジャンセンCEOが説明していることを思い出した。つまり「King of AI」のCEOは、既にいち早くこの状況を察知して、既に考え方を説明して布石を打っていたのかも知れないということだ。冒頭約21分程度が過ぎた、まだまだ序の口の部分で「Let’s talk about AI, Artficial Intelligence」と切り出して始めたのが、このAIの「Scaling Law」の話なのだ。
もし、OpenAIのLLMモデルを蒸留してDeepSeekが出来たという話、更には、1月20日のランプ大統領の就任式と同日にDeepSeekが新しい「DeepSeek-R1」をリリースし、一方で、その翌日には例の「Stargate Project」がホワイトハウスで発表されるという話などがジャンセンCEOの耳に一切入っていなかったとするならば、これはかなり偶然の単なる一致と言えるのかも知れない。だが、1月6日のCES2025の段階で、ジャンセンCEOは敢えてこの説明をしている。どちらかと言えば、リアルタイム・レイトレーシングの話の後に、「Let’s talk about AI, Artficial Intelligence」と話題を変えてまで挿入した感じのある話とも感じられ、特別な意図があったのだろうと今なら推察するが、当時は「なんでいきなり、こんな小難しい話を始めたのかな?」と悩んだのも事実だった。実際、これには会場もシーンと静まり返ったまま、かなりすべっている印象で終わったテーマの一つだ。
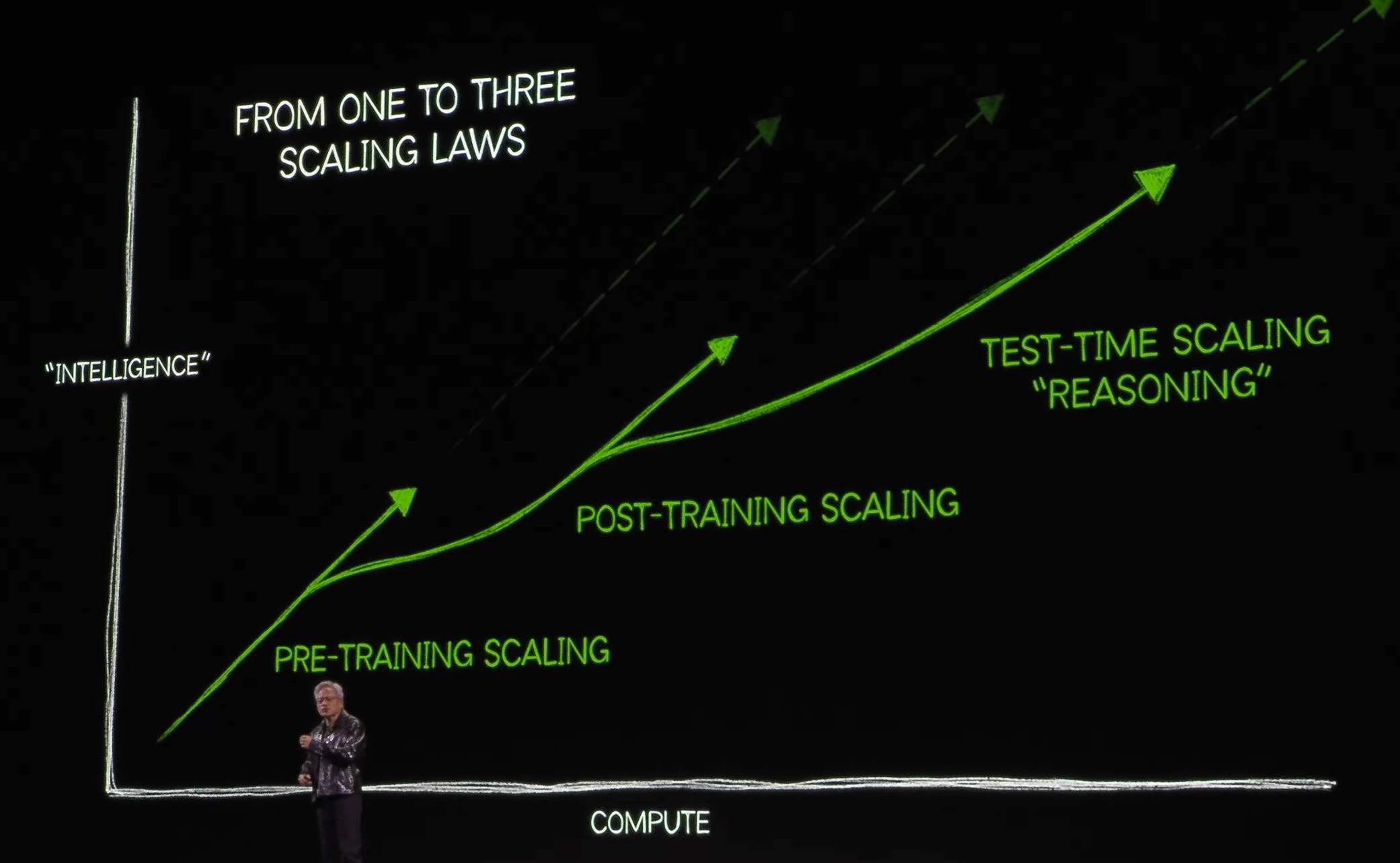
このシーンでジャンセンCEOが説明したかったことは「AIモデルは、学習・トレーニングを経て進化し、さらなる推論力を獲得することで、指数関数的な成長を遂げます。この進化には、膨大な計算リソースが必要であり、それを支えるのがNVIDIAのGPUです。エントリーレベルのAIモデルも、裾野が広がることで、次第にハイエンドモデルへと進化していきます。この流れは、AI市場全体の発展を加速させ、技術の新たな可能性を切り開く鍵となることでしょう。」ということだった。これを「Scaling Law」(スケーリング法則)と呼ぶ。
具体的には、プレトレーニングとは、AIの基礎を作るための段階で、多くのスタートアップのAIやLLMがここに該当する。データを学習し、基本的な機能を持つモデルが広がることで、AIの利用が民主化されるとても重要な段階だ。そしてポストトレーニングというのは、AIモデルがさらに高度な性能を求めて特化する段階で、特定の分野やタスクに応じて最適化され、フラッグシップモデルや次世代AIに進化する過程だ。そしてテストタイムスケーリングという、実際に使われる場面での推論能力を最大限に引き出す段階がある。ここでの進化には、膨大な計算力とネットワークの支援が必要となり、これがAIをトップクラスAIに変える鍵となるということだ。
前述のAnthropicの共同創設者でありCEOのダリオ・アモディ氏はDeepSeekの最近のリリースである 「DeepSeek-V3」 と 「DeepSeek-R1」 について、詳細に分析しているが、彼の主張を整理すると、以下のようになる。
(1) DeepSeek-V3(2023年12月)
- これは 「純粋なプリトレーニングモデル」(Pre-Training Scaling)
- 一部のタスクで米国の最先端モデル(Claude 3.5, GPT-4oなど)に匹敵する
- しかし、依然としてClaude 3.5 Sonnetより劣る分野もある(特に「実際のコーディング」など)
- DeepSeekが達成した成果の多くは 「効率的なエンジニアリングの工夫」 によるもの
- 例:Key-Valueキャッシュの最適化
- 例:Mixture of Experts(MoE)の改良
従ってDeepSeek-V3は「画期的なブレイクスルー」ではなく、技術的な工夫の積み重ねによる成果であり、つまり従来のScaling Lawの範囲内の成果ということ。驚異的なコスト削減でもない。
(2) DeepSeek-R1(2024年1月)
- これは 「強化学習(RL)を追加したモデル」(Post-Training Scaling)
- これは OpenAIのo1-previewと類似したアプローチ
- 「推論能力(数学・論理)」の向上が顕著
- ただし、強化学習の適用規模がまだ小さいため、急成長できた(Shifting the Paradigmの影響)
従って、R1はV3の単なる延長であり、技術革新ではない。現在は「交差点」にいるため、中国でも競争できるが、最終的には再びScaling Lawの支配下に戻るとしている。
またアモディ氏は、「DeepSeekが$6M(約9億円)で米国の数十億ドル規模のモデルに匹敵するものを作った」という市場の評価を誤解だと指摘した上で、DeepSeek-R1の発表によるNvidia株の急落(約-17%)は不合理 だとも主張していた。
- DeepSeekの成功は、Nvidiaにとってネガティブではない
- なぜなら、DeepSeekがAI開発を進めるには、大量のGPU(Nvidia製品)が必要
- むしろ「中国AIの進展」はNvidiaのビジネスにとって追い風(需要が増える)
- DeepSeekの成果は「過去のトレンドの範囲内」であり、突然のブレイクスルーではない
- Nvidiaの株価急落は、誤解による市場の過剰反応だった可能性が高い
- 本質的には、AIの進化に伴って、より多くのGPUが必要になる構造は変わらない
つまり「短期的な市場のリアクションは間違っていた可能性が高い」と結論付けている。これはエヌビディアのジャンセンCEOのCES2025でのプレゼンテーションとも全く整合的であり、少なくとも最も今現在でAIの技術動向に関して信頼出来る専門家(大御所?)によるコメントの解析結果と言える。
お分かり頂けるだろうか?当然のことながら私はAIの技術者でも、専門家でないが、正に2006年のGPGPUという段階からこのAI革命の流れをリードし、その先頭を引っ張るエヌビディアのジャンセンCEOと、その生成AIを世の中に認識させるきっかけとなったOpenAIの共同創設者であり、現在Claude AIを運営するAnthropicのダリオ・アモディCEOの2人が、このように見ているということだ。当然、自分たちの利害関係の為にコメントしたり、ブログを書いたりしている可能性は否定しないが、技術評価の部分で嘘をつくことは米国では出来ない。市場関係のどんな識者や評論家よりも確実なことを記していると考えるが、この先の判断は個々のご判断となる。
右肩上がりのビジネス・トレンド
いよいよ決算発表シーズンとなったが、先週は29日にIBM(IBM)、メタプラットフォームズ(META)、そしてマイクロソフト(MSFT)、翌30日にアップル(AAPL)の決算発表が行われた。実際、これもあって恐らく予想通りの展開となるであろうFOMCまでは、さすがに手が回らなかった。だがこの4社の決算内容から、今のAI革命の状況が、またひとつ色々と明らかになったのも事実。まずは一つずつ、ご紹介していこう。
マイクロソフト(MSFT)の先々はやや暗い
会社側決算説明の概要をまとめると、ポイントは以下の通りに整理出来た。
- AI関連の収益成長は強いが、供給制約が続く
- AI関連の売上は急成長しているが、GPU不足などの影響で成長に制約がかかっている。
- AIインフラへの設備投資を継続するが、短期的な供給問題がある。
- Azureの成長率が予測の下限
- Azure AIの成長は好調だったが、非AIのAzureの成長が市場予想を下回った。
- 企業のクラウド移行がAI中心になりつつあり、クラウド全体の成長戦略を調整中。
- CopilotとM365の成長が収益に寄与
- Copilotの導入が進み、収益への貢献が拡大。
- ただし、価格設定や普及のスピードが今後の成長に影響を与える。
- 設備投資の持続性
- AIインフラへの投資が続くが、FY26以降は成長ペースが鈍化予定。
- OpenAIとの契約が継続されるが、今後の資本投資のバランス調整が求められる。
サッとこの整理を見て、何か不整合を感じる部分は無かっただろうか?今回の決算発表では、会社側はクラウド事業を中心に成長が続き、AI関連の収益が拡大していると発表した。だが詳細を押さえると、実は説明がちぐはぐな部分が多い。今回、Azureの成長率が予測の下限となっていたことが、市場の期待値に届かなかった理由に挙げられたのだが、その理由が「GPUの供給制約」だったからだ。だからこそ、市場はやはり「GPUの供給制約なんだ」、つまりBlackwellの供給が遅れているのだとばかりに機敏に反応した。
だが一方で、CFOのエイミー・フッド氏はハッキリと「まず、はっきりさせておきたいのは、問題は非AIのACR(Azure Consumption Revenue)の部分にあるということです。Azure AIの業績は、運用チームの素晴らしい対応により予想を上回りました。一部の納品スケジュールを数週間単位で前倒しできたことが要因です。」と断言している。つまり、GPUは数週間単位で前倒しで納入されたということだ。言い換えると、Blackwellが納入されているということだ。これは「現在Blackwellはフル生産しています」とCES2025でジャンセンCEOがコメントした内容と整合しているし、またOpenAIのアルトマンCEOが「Blackwellが納入されて計算速度が30倍になった」と感謝しているコメントにも符合する。一方で、非AI側の課題は、主に「スケールモーション」と呼ばれる営業活動の手法にありました。具体的には、パートナー経由や間接販売の顧客へのアプローチです」と明言している。つまり営業の失敗が原因だということだ。
更にCFOのコメントを続けると「顧客は、AIワークロードへの移行と、これまで進めてきたクラウド移行(マイグレーション)や基盤の最適化とのバランスを取ろうとしています。そこで、私たちは昨夏に営業戦略を変更し、これらのバランスを取ることに重点を置きました。このような変更を行う際には、顧客やパートナーとともに、どこに投資を振り向けるか、マーケティング資金をどう配分するか、そして何よりも営業リソースをどこに配置するかについて試行錯誤を重ねる必要があります。」という。AI需要の急増にリソースを割きすぎて、従来のクラウドサービスに割く営業資源が減ったのでは?と考えざるを得ない。
一方でAWSやGoogle Cloudが価格競争を加速しており、特にAWSは企業向けのインセンティブを強化している。結果、企業はAI関連のワークロードを優先する一方で、非AIのクラウド支出を見直す傾向があり、既存のクラウドワークロード(非AI分野)はコスト削減の対象になった可能性が高いということだった。
マイクロソフトの決算発表は、「AIの成功」と「GPU不足」という要素を強調していたが、実際には、AIとは無関係な営業戦略のミスが主因であり、AIブームを隠れ蓑にして「言い訳」しているようにも見える。だとすれば、Q3・Q4で非AIワークロードの回復が見られなければ、Azureの成長鈍化が構造的な問題として認識される可能性があるだろう。
マイクロソフト固有の問題か、それとも業界全体の問題か?
今回のAzureにおけるAIワークロードと非AIワークロードのカニバリズムは、マイクロソフトだけの問題なのか、それともAWSやGoogle Cloud(GCP)にも影響を与える業界全体の構造的な課題なのかを考えておく必要がある。クラウド事業の基本構造として、クラウドプロバイダーは、基本的に汎用コンピューティング(非AI)と特殊コンピューティング(AIやHPC)の両方を提供している。そしてAIワークロードが爆発的に成長すると、リソース配分を調整する必要から、非AIのリソース(通常の仮想マシン、データベース、ストレージなど)に回すべきリソースを削る可能性がある。その結果、営業リソースの優先順位が変わり、非AIワークロードの成長が鈍化する可能性ということだ。この問題はAWSやGCPでも起こりうる話であり、マイクロソフト固有の問題とは言い切れない。ならば、AWSやGCPでは同じような問題が生じているのかといえば:
- AWS
- AWSは引き続き成長を維持しており、AIワークロードも順調に拡大。
- ただし、AWSはクラウド全体のシェアが最も大きく、AIワークロードだけにリソースを集中させる必要がない。
- 非AIワークロードの市場シェアが圧倒的に大きいため、AIとのカニバリ問題が生じにくい。
- GCP
- Google CloudはAIワークロードに積極的だが、GoogleのAI技術(Gemini、TPU)との連携が強いため、AIワークロードのインフラ配分をある程度コントロールしやすい。
- 一方で、Google Cloudは非AIワークロードでAWSやAzureに比べてシェアが小さいため、そもそも非AIワークロードの基盤が脆弱。
- GCPでは、AIワークロードの拡大がクラウド全体の成長を支える方向に作用しやすい(非AIとのカニバリが問題になりにくい)。
という状況だと考えられる。一方のマイクロソフトに特有の問題点を挙げると、やはりOpenAIとの提携でAI需要が急増し、AzureのAIインフラがフル稼働のため、AI向けのリソース確保に追われ、非AI向けの営業や投資が後回しにされたということになりそうだ。2四半期前の決算発表時から、常にAIリソースが足りないことで、機会損失が発生しているとサティアCEOはコメントしていたのも記憶にある。実はこれはとても大きな問題を示唆していたのかも知れない。生成AIが市場の注目を集めるようになったのは、正に2023年初めにOpenAIへマイクロソフトが数10億ドル投資をすると発表したことがきっかけだ。だが、そのマイクロソフト自身が、OpenAIの旺盛なAIコンピューティング・ニーズに対応・依存するあまり、通常の伝統的なクラウドコンピューティングのニーズ、つまり非AIワークロードがおざなりになった、という可能性だ。
だが、ここまで順調に成長している思われていたAzureについて、実は現時点でも、マイクロソフトのAIワークロードの大部分はOpenAIが牽引している可能性が高く、Copilotや企業向けAIツールの需要もあるにはあるが、それだけでAzureのAIワークロードを成長率157%(前年同期比)にまで押し上げるとは考えにくい。現状ではOpenAIのクラウドインフラは基本的にAzureに依存しており、OpenAIの全てのAPI(ChatGPTやDALL·E、Whisperなど)のホスティングがAzure上で行われている。更に、OpenAIの新モデル開発(GPT-5やStargate)には膨大な計算リソースが必要ということで、AIワークロードのニーズは極めて強い。その一方で、伝統的なビジネスとしてマイクロソフトらしい部分のCopilotやAI PCの影響はまだ限定的だ。
だからかも知れない。OpenAIが開発を進める次世代超大規模AIモデル(AGIに近いもの)であるStargate Projectに対して、サティアCEOが決算発表で「OpenAIの成長はAzureにとって大きなメリット」としつつも、Stargateの話には慎重な態度を取ったことが何かを示唆している。もし、マイクロソフトがOpenAIへの投資を抑制すれば、AzureのAIワークロードの成長鈍化に直結する可能性は大だ。
実はマイクロソフトのCopilotと、Copilot+PCと、更にMicrosoft 365、Dynamics 365といったサービス、誰の目から見ても実に分かり難い。
- Copilot(汎用)というのはMicrosoftのAIアシスタントの総称
- Copilot for Microsoft 365というのは、Microsoft 365(旧Office 365)に統合されたCopilot機能のことだ。Word, Excel, PowerPoint, Outlook, Teams などのアプリでAIアシスト機能を提供する。
- Copilot for Dynamics 365というのは、Dynamics 365(MicrosoftのCRM/ERPソリューション)に統合されたCopilot機能で、営業、マーケティング、カスタマーサポート、財務管理などの業務をAIで支援する。
- Copilot in Windows(Copilot+ PCとは別)というのは、Windows 11 に統合されたCopilot機能で、タスクバーから起動し、AIアシスタントのように使える。ただし、主に「検索」「質問回答」「システム操作支援」程度の機能であり、本格的な生産性向上には直結しない。
- Copilot+ PCは、ローカルでAIを動作させるためのPCハードウェア仕様を指す
- NPU(Neural Processing Unit)が搭載されたPCで、AI処理をクラウドではなくローカルで実行できる。
- 例えば、オフライン環境でもAI機能を使える。
- Copilot+ PCはハードウェアの概念であり、Copilotのソフトウェアサービスとは別。
- 現在のところ、Copilot for Microsoft 365との完全な統合はまだ進んでいない。
正直、私も今回、マイクロソフトの決算内容を整理しながら、自分のサブスクリプションの状態をチェックしてみて、あらためて無駄なサブスクリプションをひとつ解約したぐらいだ。余りにも分かり辛く、こちらは使い勝手が悪い。今回のマイクロソフトの決算は、多くの問題点を示唆していたと見ることが出来る。株価が冴えないのも頷ける。
メタプラットフォームズ(META)は加速する可能性大だが・・・
今回、メタプラットフォームズの決算発表に際して注目したのは、まずはザッカーバーグCEOが、中国発のDeepSeekが登場したことについて、どう受け止めているかの確認だ。何故なら、オープンソースという共通項を持っているから。そしてもうひとつは、メタプラットフォームズの独自シリコン(MTIA)とエヌビディアGPUとの関係の方向性だ。従来、メタはエヌビディアGPUのトップクラスのヘビーユーザーであり、独自ASICの開発・利用促進が、今までのエヌビディアGPUとどう関わるのかを確認したいと考えたからだ。
まずザッカーバーグCEOは中国発のDeepSeekが登場したことについて次のようにコメントしている。
- オープンソース戦略の優位性:
MetaのLlamaシリーズは、オープンソースとして広く利用されているが、DeepSeekの登場によってグローバルなAI市場においてオープンソースの「標準」をどの企業が主導するかが重要になったと認識している。「世界のオープンソースAIの標準をアメリカ発のものにするべきだ」という方針を強調し、MetaがLlama 4を通じて市場をリードする意向を示した。 - 技術革新の影響:
DeepSeekは推論(inference)の効率化を大きく前進させる可能性があり、これがAI市場全体の計算コストの低減に寄与する可能性があると認識している。Metaとしても、AIのトレーニングと推論のバランスを調整し、適切な計算リソースの最適化を行う方針を示した。 - AIインフラへの投資:
Metaは、Llama 4の開発とAIエージェントの進化を支えるため、今後も大規模な計算リソース(GPU・データセンター)に投資を行う計画である。特に、AI推論の計算リソースへの需要が高まる中で、AIトレーニングと推論のリソース配分の最適化が重要になると述べた。
そもそもMetaの目標がLlama 4を「最も高度で広く使われるオープンソースAI」にすることであり、それによってオープンソース戦略のリーダーシップを確立することだという。ご承知の通り、MetaはLlama 3やLlama 4を開発し、オープンソースとして提供している。しかし、直接的にLlamaの使用料を取って収益化しているわけではない。では、どのようにしてLlamaの開発に投資し、それを収益につなげているのか?結論から言うと、MetaのLlama戦略は「直接収益化」ではなく、「エコシステムの拡張と自社サービスの強化」による間接的な収益化を狙っている。以下、詳しく解説する。
(1) 自社サービスでの活用 (広告事業の強化)
Llamaは、Meta AI(MetaのAIアシスタント)や、広告配信システム、フィードの推薦アルゴリズムに統合される形で使用されている。
- 広告事業の高度化
- LlamaはMetaの広告アルゴリズムの高度化に貢献し、広告のターゲティング精度を向上させる
- よりパーソナライズされた広告を表示することで、広告主のROIを向上し、広告収益を増加させる
- Metaの広告収益は2024年Q4で468億ドル(前年比+21%)と好調であり、この成長をAIが支えている
- コンテンツ推薦の改善
- FacebookやInstagramのフィードにおいて、Llamaを活用することで、ユーザーにとって最適なコンテンツを推薦
- 滞在時間やエンゲージメントを向上させ、広告の表示機会を増加させる
これにより、Llamaは直接ではなく、「Metaの広告ビジネス全体の成長」に貢献する形で収益化されている。
(2) AIアシスタント「Meta AI」の成長と将来的なマネタイズ
Llamaを搭載した「Meta AI」は、すでに7億人以上の月間アクティブユーザー(MAU)を獲得しており、今後の収益化が期待されている。但し、現時点ではまだ日本では「Meta AI」は利用可能となっていない。Metaは2025年の計画として、Meta AIの規模をさらに拡大し、10億人規模の利用者を獲得することを目標としている。その後、次のような形でマネタイズする可能性がある。
- AI広告(広告付きAIアシスタント)
- Meta AIがユーザーの質問に答える際に、関連する広告を表示(Google検索の広告モデルに近い)
- AIの検索結果の中に、広告を自然に組み込む(ショッピング、旅行、レストラン予約など)
- 企業向けのAIサービス
- 企業がMeta AIをカスタマイズし、顧客対応やマーケティングに活用できるB2Bサービスを展開
- 企業向けに「カスタムAIエージェント」を提供するビジネスモデル
- 有料版(サブスクリプション)
- 高度な機能や商用利用向けに、「Meta AI Pro」のような有料プランを提供する可能性
- 企業向けのAPIサービスを提供する形も考えられる
(3) オープンソース化による「エコシステム拡張」と市場支配
Llamaはオープンソースとして提供されているため、直接的なライセンス料は取っていない。しかし、オープンソース化には以下の「間接的な利益」がある。
- Llamaを業界標準にすることで「開発者の囲い込み」
- Llamaを利用する開発者が増えれば、MetaのAIエコシステムが拡大し、将来的にMetaのサービスを利用する企業やユーザーが増加する
- これはAndroidがオープンソースでシェアを拡大し、Google Playや広告で収益を上げたのと類似
- AI開発コストの低減
- 多くの開発者がLlamaの改良に貢献することで、Metaは「自社開発だけでなく、コミュニティの力を活用」できる
- これはGoogleの「TensorFlow」や「Kubernetes」戦略と同じであり、オープンソース化することで業界のデファクトスタンダードを目指す
- AIチップのコスト最適化(Nvidiaへの交渉力強化)
- Llamaが広く使われることで、サーバーやクラウド事業者がLlama向けの最適化を進め、MetaのAI運用コストが下がる
- さらに、Llamaの普及が進めば、Nvidiaや他のチップメーカーと価格交渉の主導権を握ることができる(Llama向け最適化を優先させることで、コスト優位性を獲得)
Metaの独自シリコン(MTIA)とNvidiaとの関係の方向性
Metaの決算説明では、MTIA(Meta Training & Inference Accelerator)という独自のシリコンチップをAI推論と広告配信のランキング最適化に投入し、2025年以降はAIトレーニングにも拡大する計画が示された。しかし、これは即座にNvidiaとの関係を完全に置き換える動きではないと考えられる。結論として、Metaは「独自シリコン」と「Nvidia GPU」の両方を活用する戦略をとる可能性が高い。市場がしばしば混乱するポイントは、「Metaが独自のシリコンを開発=Nvidiaのシェアが奪われる」と単純に捉えられがちな点だが、実際にはそれほど単純な話ではない。
MetaがMTIAの開発に力を入れる背景には、「最適化」「コスト削減」「供給の安定化」という3つの要因がある。
- 最適化の必要性
MetaのAI推論・広告ランキング・コンテンツ推薦のワークロードは、一般的なトレーニング向けGPU(Nvidia H100など)とは異なる要求を持つ。特に推論のワークロードは低消費電力・低遅延が求められるため、NvidiaのGPUよりも自社専用チップの方が効率的になる可能性がある。 - コスト削減の必要性
AIのインフラコストは年々増加しており、Metaの2025年の設備投資(CapEx)予算は600億〜650億ドルと巨額である。長期的に見れば、独自のチップを開発し、特定用途に最適化することでコストを削減できる可能性がある。 - サプライチェーンの安定化
現在、NvidiaのGPUは需要が供給を大きく上回っており、確保が困難な状況が続いている。独自のチップを開発することで、Nvidiaの供給状況に依存しすぎるリスクを低減できる。
Metaは決算説明で明確に「今後もNvidiaのチップを購入する」と述べており、Nvidiaとのパートナーシップは維持されると考えられる。その方向性を整理すると、以下のようになる。
- NvidiaのGPUは主にAIトレーニングに活用
- Llama 3やLlama 4といった大規模言語モデル(LLM)のトレーニングには引き続きNvidiaのA100/H100/B100クラスのGPUが使用される可能性が高い。
- AIモデルのトレーニングには大量の計算資源が必要であり、ここでは汎用性の高いNvidiaのGPUが引き続き不可欠となる。
- MTIAは推論(Inference)と広告ランキングに特化
- AIの推論(Inference)、広告の最適化、コンテンツの推薦システムなどは、MTIAのようなカスタムシリコンで処理する方が効率的である可能性がある。
- 2024年時点では、MTIAは広告の推論にのみ適用されているが、2025年にはトレーニングワークロードにも拡張予定であると発表された。ただし、すべてをカバーするわけではない。
- Metaはハイブリッド戦略を採用
- 一部の用途(推論やランキング)ではMTIAを活用しつつ、Nvidiaの最新GPUも継続的に購入するというハイブリッド戦略を採用する。
- これは、GoogleがTPUを開発しつつNvidiaのGPUも併用している戦略と類似している。
このため、Metaが独自のチップを開発したからといって、Nvidiaのビジネスが直ちに脅かされるわけではない。むしろ、MetaのAI事業が拡大することで、トレーニング向けのNvidia GPUの需要は引き続き強いままであると考えられる。市場が混乱しやすいのは、「独自シリコンの採用=Nvidia排除」と短絡的に捉えがちだからである。しかし、これまでの他社の動きを見ても、以下のように「共存」が主流となっている。
- Google
- TPU(独自シリコン)を開発しつつ、AIトレーニングの一部にNvidia GPUを使用
- Microsoft
- Azure向けの独自チップ(Athena)を開発しながらも、NvidiaのH100を大量に導入
- Amazon AWS
- Inferentia(推論用)やTrainium(トレーニング用)を開発しつつ、Nvidia GPUも併用
Metaも同様の方向に進むと考えられる。つまり、「それはそれ、これはこれ」という形で、MTIAとNvidiaのGPUは共存し、MetaのAIインフラ全体が拡張されるというシナリオが妥当である。特に、NvidiaはBlackwell(B100シリーズ)の投入を始めており、これは大規模AIトレーニングに適したGPUである。MetaがLlama 4以降のモデル開発を進める中で、こうした最新のNvidia GPUは依然として重要な役割を果たすと考えられる。
METAのスマートグラスが次のプラットフォームになるかも?
もしスマートグラスが次世代のコンピューティング・プラットフォームになった場合、Metaはビジネスモデルを変える可能性が高い。スマートグラスがエッジAIになり、そこから還流されるデータでLlama 4を継続学習(Post-Training Scaling or Test-Time Scaling)するのは、極めて強力な戦略だ。これは、テスラの自動運転データ収集と似たコンセプトであり、AIの継続学習をリアルワールドのデータで行える点が大きな強みとなる。
現在のMetaの主な収益源は、 広告($46B/四半期)、ハードウェア販売(Quest, Ray-Ban Meta)、サブスクリプション(WhatsApp Business, Meta Verified) だが、スマートグラスの普及によって、以下の新たな収益モデルが生まれる可能性がある。
可能性のある新ビジネスモデル
- 「AIアシスタント」課金(SiriやChatGPTのような収益化)
- Meta AIのプレミアム版をサブスク提供
- B2B向けのAIコンサルティングサービス
- 「スマートグラス × 広告」モデル
- 視界に表示されるパーソナライズド広告
- 「音声広告」「AR広告」の新規市場を創出
- エッジAIを活用し、リアルタイムに広告を最適化
- 「AIデータストア」モデル
- スマートグラスで収集したデータを「許可されたパートナー企業」に販売
- 自動運転・ヘルスケア・マーケティング業界向けに「AIデータサービス」展開
- 「スマートグラス OS」提供
- AppleがiOSでApp Storeを握っているように、Metaが「AI OS」を展開
- 開発者向けにMeta AIアプリのエコシステムを構築
- スマートグラスアプリの収益モデルを手数料ベースにする(App Storeモデル)
これらのことから考えて、メタプラットフォームズ(META)のポテンシャルは想像以上に高いと感じる。ただ、そのリスクとしてはオープンソースのLlama4などが、オープンソースが故の問題点に突き当たる可能性は考えておく必要がある。また日本の投資家としては、まだMETA AIにしても、いわんやスマートグラスにしても、まだ試してみることさえ出来ないということだ。ただ、FacebookとInstagramの会社という捉え方が、逆に誤解を招く可能性も高いということも指摘しておきたい。
International Business Machine(IBM)がAMDを救う
IBMのAI関連の売上・受注が急成長していること、ソフトウェア部門(特にRed HatとTPP)が強く、キャッシュフローが増加していることが市場のポジティブな反応を引き出した要因。2024年の売上成長率は3%、フリーキャッシュフロー(FCF)は127億ドルと、数年来で最高水準となった。特に、企業向けAIソリューションとコンサルティングの組み合わせが今後の成長の鍵となる。
- GenAI関連ビジネスが50億ドル規模に到達(前四半期比+20億ドル)。
- コンサルティング部門のGenAI案件が全体の4/5を占め、AIが事業の中心に。
- Watsonxファミリー、Graniteモデル、RHEL AI、OpenShift AIなどの成長が順調
- AMD、SAP、Microsoft、CoreWeaveとのパートナーシップ強化。
- Neural Magicの買収でモデル最適化技術を強化、HashiCorpの買収も進行中。
- Red Hat関連の売上が30億ドル規模になり、成長のドライバーに。
IBMは、企業向けのAI導入において、ハードウェアとソフトウェアを組み合わせた最適なインフラ提案を行うことが強みだ。IBMのコンサルティング部門は、単にソフトウェアを導入するだけでなく、どのAIワークロードをどのハードウェア上で動かすべきかを含めた包括的な提案をする。その中で、Nvidia、AMD、CoreWeaveがどのように関わっているのかを整理してみよう。
NvidiaのGPUをAIワークロードのメインオプションとして提供
- IBMはNvidiaのGPUを活用したAIソリューションを提供することが多く、企業が大規模なLLM(大規模言語モデル)やAI推論ワークロードを動かす際にNvidiaのH100、A100、最新のB100、Blackwellシリーズを活用。
- Watsonx.aiやWatsonx.dataがNvidia GPUを活用できる設計になっている。
- Red Hat OpenShift AIもNvidiaのCUDAベースのワークロードをサポートし、企業が簡単にGPUクラスタを活用できる環境を整備。
AMDのGPUは、そのコスト・性能のバランスを考慮した選択肢
AMDの利点としては、メモリ容量の大きさ(192GB HBM3メモリ)と低コストが挙げられ、Nvidia H100よりもコストパフォーマンスが良い選択肢としてIBMの提案に組み込まれている。
- Nvidia H100の代替としてMI300Xを推奨するケースが増えている(特にクラウドコストを抑えたい企業向け)。
- Neural Magic(IBMが買収)と組み合わせてAMDのMI300X上で効率的なモデル推論を可能にする方向性。
- メインフレーム(IBM Z)やPowerサーバーとの統合AIワークロードにAMDを活用するケース。
- MI300シリーズがIBMのコンサルティングにおいて提案される主なユースケース
- 生成AIのファインチューニング(特にRed Hat OpenShift AIと組み合わせて)
- ハイブリッドクラウド環境でのオンプレAIワークロード
- SAPなどのエンタープライズアプリケーション向けのAI推論
- IBMの独自AI(Graniteモデル)をAMD GPU上で動作させる最適化
CoreWeaveがIBMのコンサルで活用されるケース
- 企業がすぐにAIを試したい場合、オンデマンドでCoreWeaveのGPUリソースを利用
- オンプレミスとクラウドを組み合わせたハイブリッドAI環境の構築
- クラウドでの分散推論処理をNvidia GPUを使って行う
アップル(AAPL)には楽しみがある
アップルの決算は、市場の予想に反して、力強い結果となった。
市場が評価したポイント
- 予想を上回る業績
- 売上高:$124.3B(前年比+4%)➡ 過去最高
- EPS:$2.40(前年比+10%)➡ 過去最高
- サービス売上:$26.3B(前年比+14%)➡ 過去最高
- 総利益率:46.9%(前年同期比+70bps)
- Apple Intelligenceの成長と影響
- AI機能を搭載したiPhone 16シリーズの市場パフォーマンスがAI非対応地域よりも好調
- 2.35BのアクティブデバイスでAI機能の普及拡大へ
- 4月には対応言語を大幅拡充(日本語、ドイツ語など)
- iPhone販売の安定
- 売上高$69.1B(前年並み)➡ 過去最高のアップグレード率
- iPhone 16は前年モデル(iPhone 15)よりも好調な販売
- Mac・iPadの成長
- Mac売上:$9B(前年比+16%) ➡ M4チップ搭載MacBook Proなどが牽引
- iPad売上:$8.1B(前年比+15%) ➡ iPad AirやiPad Miniの売れ行き好調
- 新興市場での強さ
- インドが特に好調:iPhoneがインド市場で売上トップ
- 中東、ラテンアメリカ、南アジアでも過去最高売上を記録
アップルの決算内容のポイントは、市場やメディアのネガティブな事前予想に反し、「Apple Intelligenceが本格展開前でも、iPhone 16シリーズが十分魅力的だった」という点にある。まず、その謎を解くには、「AIとは何か?」という一般的な理解を整理することが重要だ。つまり「AI」という同音異義のたぐいの整理だ。現在、AIという言葉が非常に幅広い技術や用途を指すため、人によって期待するものや関心のある領域が異なっている。炊飯器についているのもAIであり、アセットアロケーションを考えてくれると称するモデルもAIとしてセールスされており、一方で、まだ殆ど見る機会がないAgentic AIやPhysical AIといったものもある。だから特にスマートフォンにおけるAIの役割を考えると、どのような形でユーザーに価値を提供するのかを明確にすることが、技術の普及と市場での成功のカギとなる。当然、投資判断の糧にもなる。一般的に「AI(人工知能)」という言葉は幅広い意味を持つが、大きく分けると以下のようなカテゴリに整理出来る。

ならば、AIがどんな人にどんな形で訴求するのか、AIの利用形態によって、どんな感じのスマホ・ユーザーに響くかを整理してみた。

つまり「Apple IntelligenceはAIを強化した」と言っても、Siriの進化を期待している人と、カメラの画質向上を期待している人では、捉え方が全く異なるだろうということだ。Apple Intelligenceの文脈で考えると、iPhoneのAI機能は以下の3つの方向で進化していくと考えられる。
ユーザー体験向上(スマホをより便利に)
- 例:カメラAI、音声認識、スマートアシスタント
- 花火を綺麗に撮影するAI(夜景補正、手ブレ補正)
- 写真の自動編集AI(合成・補正)
- Siriの自然言語理解が向上(よりスムーズな会話)
- メールやメッセージの要約・整理AI
「AIがいることで、普段の操作がより簡単に、より美しくなる」という体験の向上。
クリエイティブ支援(コンテンツ作成の手助け)
- 例:生成AI、画像・動画編集
- 写真加工AI(Image Playground):インスタ用の画像を簡単に加工
- AI動画編集:ショート動画を自動で作成
- Genmoji(Apple版絵文字生成AI):オリジナルの絵文字を生成
「AIがコンテンツを作ってくれる」ことで、誰でも簡単にクリエイターになれる。
情報整理・サポート(AIが考える)
- 例:検索・要約・リコメンド
- メールの要約(1日100件のメールから重要なものだけ整理)
- メモやドキュメントの要約
- 自動翻訳・字幕生成(旅行中の翻訳やビジネス会話)
「情報処理をAIが代わりにやってくれる」ことで、時間を節約できる。
Apple Intelligenceの方向性としては、Googleのように「AIが世界の知識を理解する」ことを目指すのとは違い、「AIが個人の体験を向上させる」ことを目指す(デバイス最適化+プライバシー保護)という方向で進んでいる。今回の決算発表を通じて、その方向性は間違っていないことが証明された。実際、私もiPhone 16 Proを利用しているが、何気なく使っている時に「あ、これAIが働いている」と驚く時がある。因みに私はiPhone 14 proからのアップグレードだ。
また別件で付言すれば、ティム・クックCEOが決算発表で「Macは最もパワフルなAI PCである」と発言している。その背景には、Apple Siliconの特定の技術と機能が関係していると考えられる。具体的に、Appleが「AI PC」としてMacの強みをアピールするとすれば、主にNeural Engineの性能とオンデバイスAIの強みを指していると言えるだろう。これはまだまだ新しい戦いが「AI PC」の世界で起きるということの暗示かも知れない。
まとめ
2月7日に日米首脳会談が行われる
漸く、我らが石破総理とトランプ大統領の首脳会談の日程が2月7日と決まったようだ。何が不安かと言えば、何もかもと言ってしまいたいぐらいなのだが、まずは従来通りの日米同盟の関係維持をきっちりと約してくることを望むばかりだ。米中関係の中に入って、上手にバランスを取れる程に外交上手とは思えない以上、不必要な手形を切ったり、要らぬ要求をしないことかも知れない。もうひとつ気になるのは、為替水準について、米政府が何か注文を付けてくることだ。もし今、ここで急激な円高にでも持ち込まれようものなら、ただでさえ関税問題でビクビクしている外需企業が軒並み失速することになるからだ。それだけは避けて欲しいと思っている。
それにしてもフジテレビの問題はあまりにも酷い。正に公共の電波を預かって情報配信をしているテレビ局として、時に政治などにも注文を付ける立場でもあるならば、最も倫理観が高くなくてはいけないというのが理想だが、反対にあそこまで低レベルということが明らかになると、あらためて情報選別に注意しないとならないことは明らかだ。そして更に恐ろしいことは、これが実際にはフジテレビにだけ限った問題では無いということだ。「報道機関」という立場を持つものを、時に審査する機関も必要なのではとさえ思ってしまうが、それが総務省の役割だとしたら、ただただ気分は暗澹たるものに変わるだけだ。
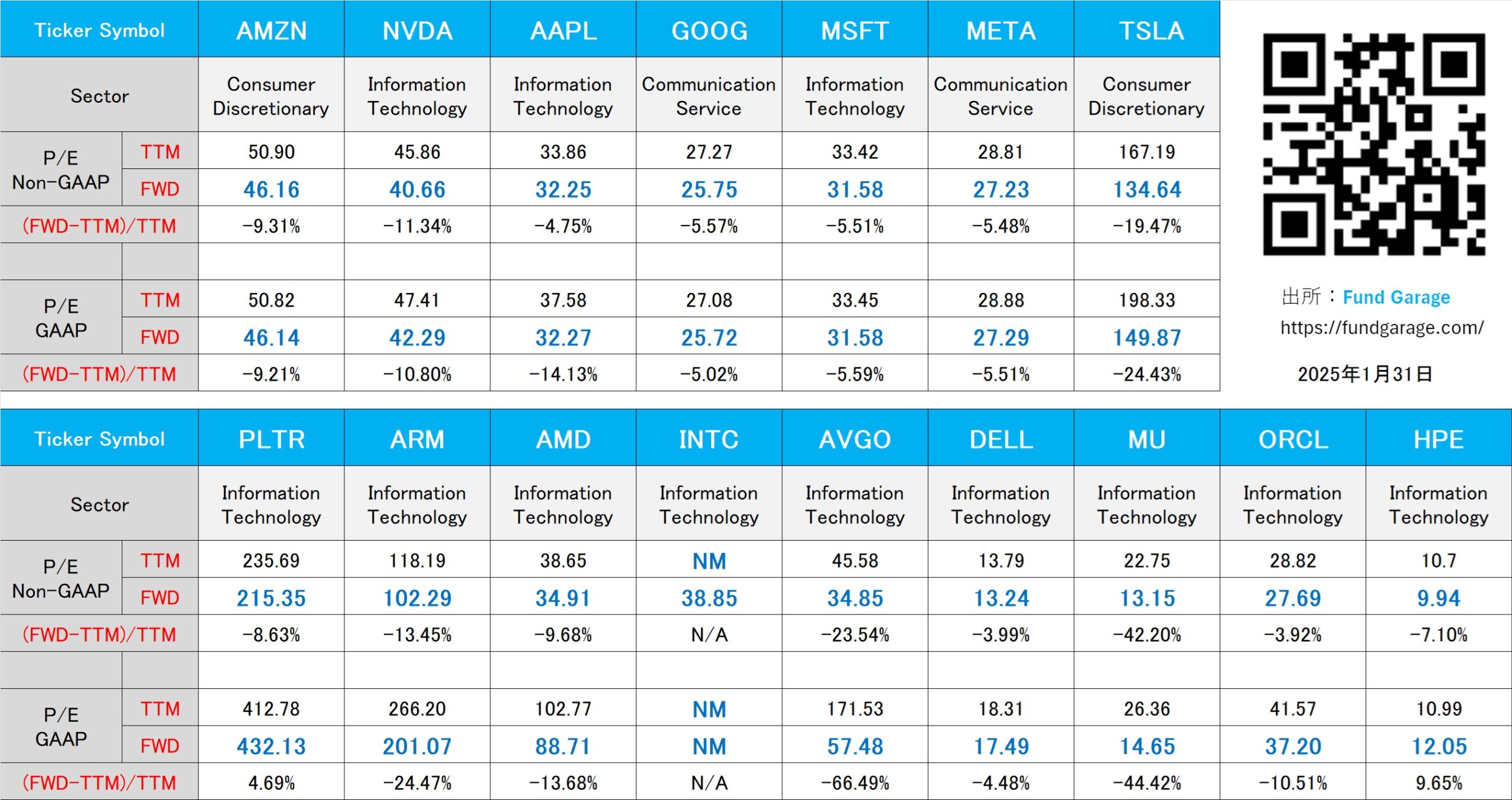
下記の表はいつもの米国株のPER(1月31日付)。