市場の構造変化──沈みゆく船に群がる者たち
今週の市場総括:「格下げショック」という虚像を超えて
先週の市場は、先々週の週末5月16日(金)引け後に発表されたMoody’sによる米国債の格下げを受け、その影響を最初に織り込む週明けの日本市場から注目された。しかし、週を通じての展開を俯瞰すれば、「米国金融資産からの逃避」や「グローバル・リスクオフ」といった一般的な見立ては、実体とは乖離していた。
5月23日時点における日米主要株価指数と、前週末比および年初来の騰落率である。主要株価指数の週間・年初来騰落率(2025年5月23日時点)

右肩上がりのビジネス・トレンド
数字で読むNVIDIA──Q1 FY2026決算のファクト整理
現地時間5月28日NY市場取引終了後(日本時間29日早朝)、待望のエヌビディア(NVDA)の決算が発表された。株価は時間外取引で、概ね約5%~6%前後の上昇となり、翌日の本市場取引では、一時141ドルも回復したが、関税問題に関わる市場全体のリスクオフムードに押されて、それでも終値ベースで139.19ドル(前日比+4.38ドル:+3.25%)となり、主要株価指数の騰落率が軒並み+0.3%~+0.4%に落ち込む中で好対象となった。市場は今回のエヌビディアの決算をそれなりにポジティブには評価したようだ。
ただ、この先のエヌビディアの株価は、決して一気に高騰するとは考えにくい。それには二つ、要因がある。ひとつめがここから上の値位には、それなりな「やれやれの戻り売り」の需給が待っていると考えらえること、そしてもうひとつが、関税リスクと対中輸出問題だ。前者は単にテクニカルな問題であるが、後者をどう読むかは、今回の決算発表のカンファレンスコールでも明らかになった、エヌビディア、及び、AI革命の構造的な理解を深めることで、投資スタンスは決まってくるものと考える。結論から先に言えば、ファンダメンタルズ的には洋々たる未来が見て取れる。だが、やはり市場の理解や認識がそこまで追い付いていないことも、カンファレンスコールのアナリストとの質疑応答、また決算発表後に出回った報道や、市場関係者のコメントを見ているとしっかりと確認出来る。
まずは、決算発表で詳らかにされた数字の確認から、エヌビディアの現状と、AI革命の流れについて、確認していきたい。
総論:数字は全て市場予想を超過、ただし含みを残す構造も
決算そのものは、売上・利益ともに市場予想を上回り、事前の市場センチメントとは裏腹に好決算として歓迎された。更に、その中身を丁寧に読み解けば、いくつかの重要な構造的変化が浮かび上がる。
まず注目すべきは、Non-GAAPベースのEPS($0.81)に、H20出荷制限に伴う在庫評価減($4.5B)が含まれていたという事実である。この点について、CFOのColette Kress氏は決算説明会の中で明言している:
“Gross margin for the first quarter included a charge of $4.5 billion for inventory related to products affected by the new U.S. export control regulations impacting sales to China and other markets. This impacted both GAAP and Non-GAAP gross margins and earnings per share.”
つまり、これは単なる一過性の会計処理ではなく、売上原価の一部としてNon-GAAP EPSにも反映されたということだ。仮にこの評価減を除外した場合、実力ベースのNon-GAAP EPSは約$0.96(=$4.5B ÷ 希薄化後株式数 約4.69B)となり、本来の収益性はさらに高かったことになる。これは、従来の「One-time chargeはNon-GAAPで調整される」という市場の前提とは異なる処理方針であり、企業側がこの在庫損失を特殊要因とは見なさなかった点に注目すべきだ。
結果として、この決算には「見かけ以上の強さ」が潜んでいたと評価できる。米中摩擦という逆風下でも、構造的な利益体質が揺らいでいないことを示した、極めて重要なシグナルである。
主要業績とコンセンサス比較
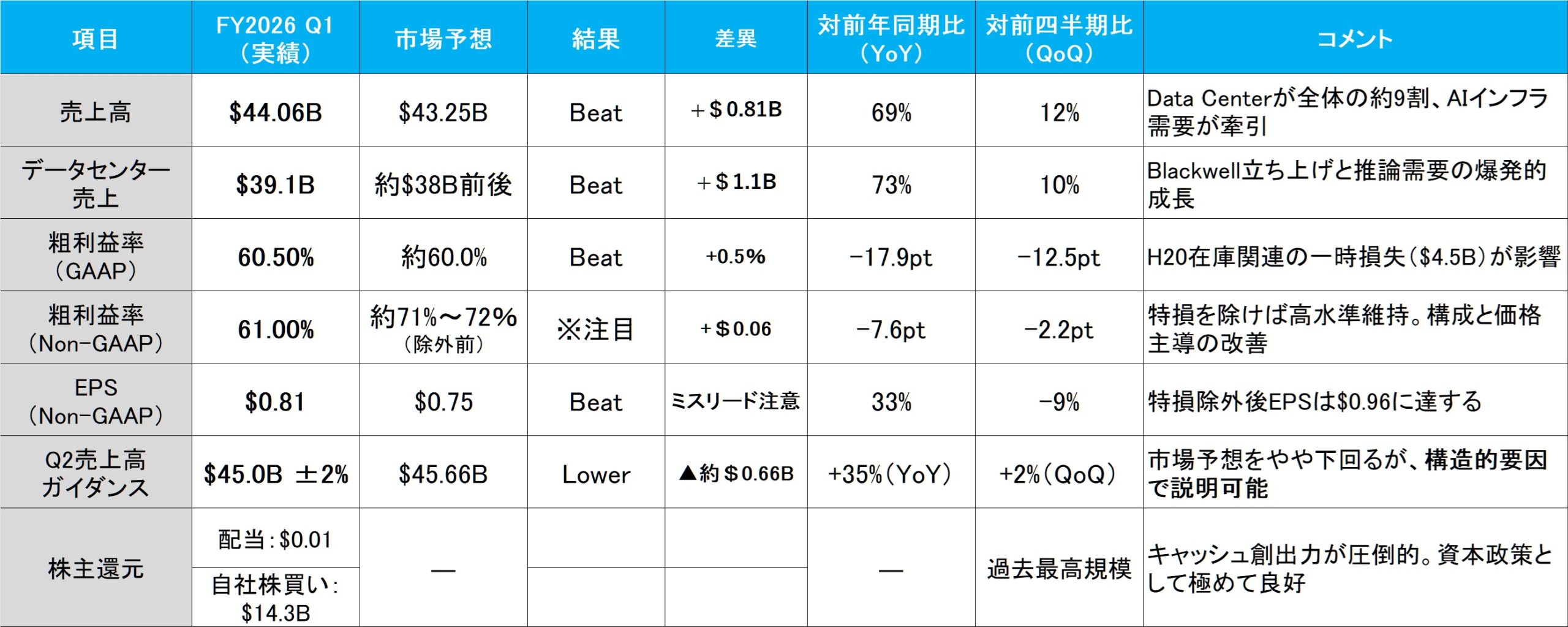
※H20在庫評価減($4.5B)を除いた実力ベースでは、EPSは $0.96 と試算される。
この構造から浮かび上がるのは、単なる“予想比の上下”ではなく、NVIDIAの成長エンジンが明確に切り替わりつつあることである。
セグメント別売上──中核はもはや“Data Center事業”ただひとつ
NVIDIAの成長の原動力は、もはや単なるグラフィックス・プロセッサの供給に留まらない。今回の決算では、それが数字としても極めて明確に表れた。以下が、セグメント別の売上構成と前年同期比の成長率である。
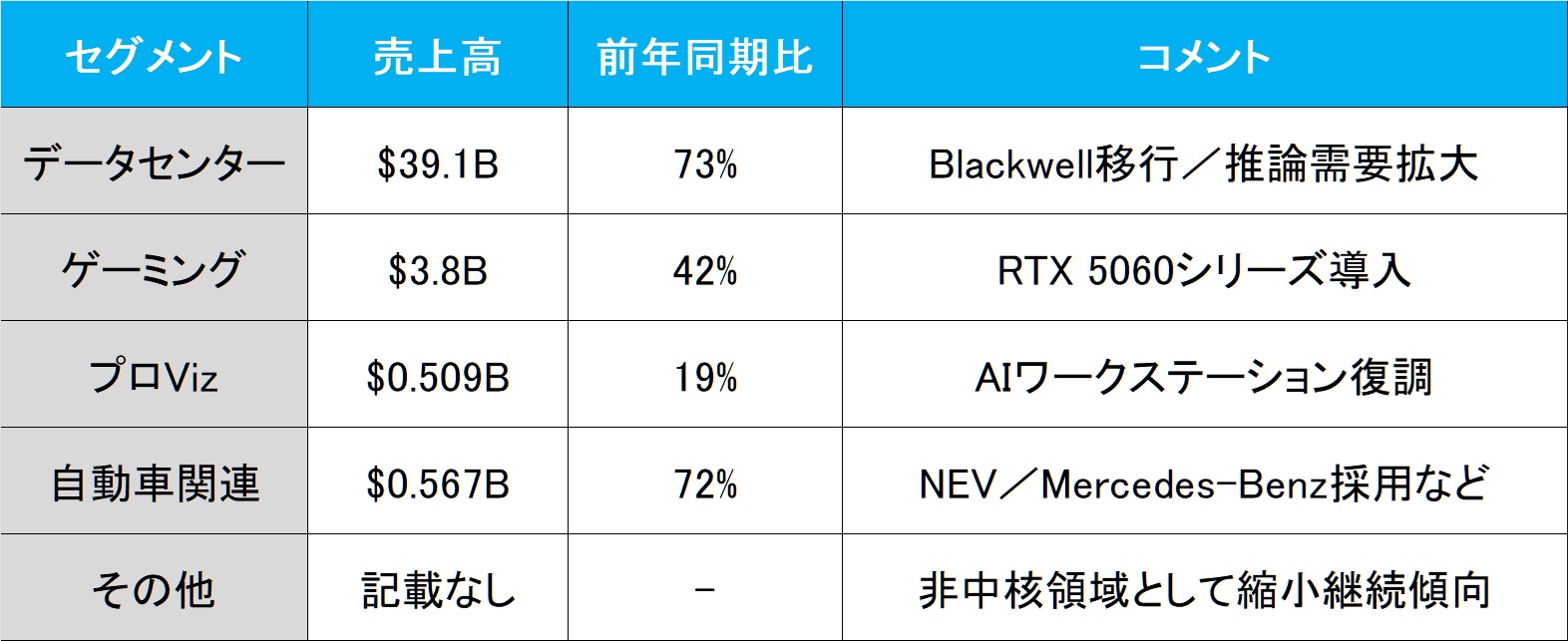
一方、ゲーミング部門の+42%成長も見過ごせないが、その絶対額は$3.8Bに過ぎず、Data Centerとの規模感の差は歴然としている。また、自動車部門も+72%と高成長だが、これはまだ“未来の種”であり、収益貢献の主軸には至っていない。
今やNVIDIAのビジネスは、Data Center=AIインフラに完全に軸足を移しており、「GPUメーカー」から「AIファクトリーの中枢部品供給者」への変貌が、数字でも裏付けられた格好だ。
H20の影とBlackwellの胎動──「失注」は終わりではなく構造転換の序章
では、そうした構造変化のさなかにおいて、中国向けH20の出荷停止とその影響は、果たして“成長の頭打ち”を意味していたのか?
答えは明確に否である。今回の決算では、確かにQ1に$4.6BのH20が出荷され、$2.5Bが未出荷となり、Q2ではさらに$8.0Bの売上が失われる見通しであると報告された。だが、その数字だけをもって「成長鈍化」と捉えるのは、構造理解の欠如に他ならない。
なぜなら、このH20の失注が示すのは、“旧い市場構成の終焉”であり、同時に“新たな構造圏への移行”の幕開けでもあるからだ。
ジャンセンCEOは、「もしこのまま中国向けの供給が続けられないとすれば、我々は最大でTAM(Total Addressable Market)ベースで$50Bの市場を失う可能性がある」と述べた。だがその発言は、将来の機会損失の警告であり、現実の見通し悪化を表すものではない。実際、同時に示されたのは、「中国以外の需要──すなわち推論用AIシステムを国家レベルで内製化しようとするSovereign AI需要──によって、この影響は十分に相殺され得る」という構造的展望だった。
さらに重要なのは、ジャンセンCEOが見せた政治的バランス感覚である。米国の対中規制には忠実に従いながらも、中国市場との接点は完全に断ち切らず、上海にR&D拠点を開設するなど「技術的人材との連携」は維持する姿勢を見せている。これは一見「親中」とも取られかねないが、実態はまったく異なる。マーケットアクセスと規制順守の間で、“地政学を経営する”CEOの意思が如実に現れている。
こうしたスタンスが可能なのは、NVIDIAが単なるハードウェアサプライヤーではなく、“計算資源を生産するインフラ企業”としての地位を確立したからに他ならない。それはもはや、米中のどちらかに属するという単純な帰属論では語れない、支配構造そのものを再設計するポジションである。
第1四半期の$4.5B評価損、第2四半期の$8Bガイダンス減額──それらは数字の上では確かに「落ち込み」に映る。だが本質的には、これはNVIDIAが次なるフェーズへ進むための“切り替えコスト”であり、その背後ではBlackwellとAIファクトリーという新しい経済構造が、すでに静かに立ち上がり始めている。
BlackwellとGPUロードマップ──「計算装置」から「AIファクトリー」へ
プロダクト系統図の読み解き
2024年のGTCで発表され、今回の決算でも繰り返し言及された「Blackwell」は、単なる次世代GPUではない。NVIDIAのAIロードマップ全体における転換点であり、「Hopper → Blackwell SGX → GB200(Grace+Blackwell)→ GB300(次世代)」へと連なる進化の中心軸に位置づけられている。
まず、Blackwellには2つの主要な形態が存在する:
- B200(Blackwell SGX):GPU単体での形態であり、従来のH100(Hopper)に相当。省電力化やスループット最適化を図りつつ、推論性能を中心に改良が施されている。
- GB200(Grace + Blackwell):NVIDIAのSuperchipアーキテクチャに基づく統合型。ArmベースのGrace CPUとBlackwell GPUを1パッケージに収め、AIワークロードにおける低遅延・高帯域接続を実現する。
さらにこのSuperchipをNVLinkで72基接続した構成が、「NVL72」というNVIDIAの次世代AIラックの標準構成であり、データセンターにおける「AIファクトリー」の基盤装置となる。ここで注目すべきは、もはや個々のGPUの性能というより、「構成単位がラック」で語られ始めている点である。ジャンセンCEOが「AIはTokenを出力するファクトリーだ」と繰り返す背景には、この物理的実装の変化──すなわちGPUが「部品」ではなく、「Token生成インフラ」の中心柱になったという根本的変化がある。
そして決算説明会では「GB300」の存在にも触れられた。これはBlackwell後継の次世代GPUであり、Grace CPUの第2世代と組み合わされる形で開発が進められている可能性が高い。市場では既に、「NVIDIAのリードタイムは2年先まで埋まっている」とされる状況下、こうした次世代構成に対するサーバー業者・ソブリンAI国家からの関心は高まっている。
論点の深掘り
▸ SGXとSuperchip(GB200)の違い
SGXは単体GPUとしてのBlackwellであり、既存のシステムへの置き換えや、H100の延長線上での利用を想定した製品である。一方、GB200は「Grace + Blackwell」による統合アーキテクチャであり、主に新規構築のAIファクトリーやソブリンAIの構築需要に応える構成だ。ここに見られるのは、GPUという「部品の入れ替え」ではなく、「データセンターの設計思想そのもの」の変革である。
▸ NVL72のスループットと供給体制
NVL72は、単体のGPU性能ではなく、ラック単位でのToken出力量=生産性を最適化する思想で設計されている。NVIDIAによれば、NVL72は従来構成(H100ベースのDGX)と比較して「30倍の推論スループット」を実現する。これはDynamoと呼ばれるソフトウェア・スケジューリングとの統合によって初めて成り立つ構成である。今期の決算において、NVL72は既にサンプル出荷段階から量産フェーズへ移行しつつあり、2025年後半以降の売上寄与が期待されている。ただし、Blackwell関連の初期マージンはHopperに比べて「やや低い」(CFO談)とされており、初期立ち上がりは利益率圧縮要因ともなる。
▸ Hopperユーザーとの摩擦
既存のH100ユーザー──例えばMeta、Microsoft、Amazon、Googleなどのハイパースケーラー各社は、現在もHopperベースのAIトレーニングクラスタを構築中である。ここでBlackwell系への移行が急激すぎると、在庫・設備投資の減損リスクやパフォーマンスの相対的劣化評価が問題となる可能性がある。だが一方で、ジャンセンCEOは慎重なバランス感覚を保ちつつ、Blackwellへの「自然な世代交代」を推進している印象が強い。今回の決算発表でも、特定顧客名は避けつつも、Blackwell系のシステムが今後の成長ドライバーとなる点を強調していた。
このように、Blackwellの登場は単なる製品発表ではなく、「供給単位がGPU → ラック → データセンター」へとシフトし、最終的には「Token出力量」が経済価値の指標となる世界観へ繋がっている。これはまさに、「NVIDIAのGPUロードマップ=AIファクトリー構想」そのものの進化過程である。
CUDAの次にある“NVIDIAの本質”──NeMo・Dynamo・NIMsが構築するAIの供給網
CUDAは、GPU時代の開発者にとって“前提”となった技術である。金融業界の分析者も「NVIDIAの強みはCUDA」と口を揃えるが、今回の決算・カンファレンスコールで改めて浮き彫りになったのは、CUDAという“入口”の先にある、NVIDIAの用途特化型ソフトウェア群が、現実に顧客価値を生み始めているという事実である。NVIDIAは今や単なるチップメーカーではなく、Token Output=生成AIの成果物をいかに“現場で使えるものにするか”という最終工程に至るまで、フルスタックで支援する存在であることを、実績で証明しつつある。
NeMo・Dynamo──顧客のAIファクトリー現場で実装が進む中間層ソフト
特に今回、カンファレンスコールでジャンセンCEOが複数回言及したのが、「NeMoとDynamoが、実顧客で価値を発揮している」という点である。
- NeMo:大規模言語モデルの訓練から推論、さらにはファインチューニングやワークフロー管理までを一貫して担うプラットフォームである。言い換えれば、“統合的なLLM運用基盤”として、企業内でAIの業務実装を支援する役割を担っている。今回の決算発表では、以下のようなNeMoの実運用例が紹介された:
- Shell:エネルギー開発オペレーションでのAI推論ワークフローにNeMoを活用
- NASDAQ:マーケットトレーディングにおけるAIエージェント生成
- Cisco:サイバーセキュリティAIの学習/運用インフラにNeMoを利用
これらの実例が示すのは、NeMoが「学習と推論の統合」「APIとモデルの接続性」「エンタープライズ適用」すべてを担える高度なプラット フォームへと進化しているという事実である。
- Dynamo:トランスフォーマーモデル推論の最大ボトルネックであるKVキャッシュの肥大化に対応し、トークンレベルでの非同期分散処理を可能にするNVIDIA独自のエンジンである。ジャンセンCEOは、「Dynamoによって最大30倍のスループット改善が実現されている」と明言。これは単なるハードウェア性能の向上ではなく、ソフトウェアによって「Token単価(Token per Dollar)」を経済的に最適化するという、新たな生産性指標を実装した意義がある。
- CrowdStrike(サイバーセキュリティ)やAmdocs(通信系BPO)が導入。
NeMoやDynamoのような中間層フレームワークが実際の企業活動の“オペレーション”の中に組み込まれて機能しているという点に注目すべきだ。NVIDIAはもはや「開発者のためのプラットフォーム」ではなく、「企業の業務設計そのものを構築するためのソリューション提供者」として、エンタープライズに深く浸透し始めている。
ロジックとしての整理:なぜCUDAだけでは足りないのか
CUDAは開発のためのインターフェースであるが、それだけでは以下の課題に対応できない:

CUDAを超える“構造支配”──Inference Economyという次章
CUDAという“GPUと開発者を繋ぐAPIの成功物語”は、もはや過去の章に過ぎないとも言えそうだ。NVIDIAが描く次の章は、Dynamoによる推論スループット最適化、NIMによるサービスとしてのAI活用、NeMoによるモデルライフサイクルの掌握──つまりInference Economyを支配する三位一体の布陣である。そして、この戦略の背後にある構造は明確だ。NVIDIAの真の優位性は、「Tokenを誰が、どこで、どう流通させるか」という構造支配の野心にある。それはもはやGPUを売るだけの企業ではなく、「AIという生産物を生み出すファクトリーを設計し、その最適化された運用までを包括的に担う存在」へと進化している。
NeMoやNIMsが目指す方向性は、単なるソフトウェアの“提供”ではない。企業の業務やシステムに対して、AIの力をプロダクションレベルで実装・適用する基盤として設計されている点に本質がある。特にNeMoは、前処理(retrieval)、推論(reasoning)、生成(generation)といった複数の推論ステージをオーケストレーションする構造を持っており、これはまさに現在進行中の「Agentic AI」時代の到来を見据えた設計思想である。Dynamoのようなツールによって、こうした複雑な構造を可視化・運用する手段も整ってきた。すでにAIエージェント構成に向けた実証事例は、金融機関やSaaSベンダーとの間で進んでいる。
また、NIMsは「NVIDIAが事前に最適化した推論モジュール」として、用途ごとにチューニングされた小型モデルをAPI経由で提供する構造であり、特にセキュリティやデータ主権が問われるエンタープライズ現場では高く評価されつつある。代表例として、SAPはNeMo・NIMsを基盤に、自社業務に最適化されたエージェント構築を始動しており、アブダビのG42やインドのRelianceなども同様の枠組みで展開中である(いずれもカンファレンスコールにて具体的に言及)。
このように、CUDAが「計算環境の統一基盤」だったのに対し、NeMoやNIMsは「推論結果が価値を持つ現場」──すなわちInference Economyの着地点におけるソフトウェアレイヤーの覇権を目指している。これは単なるアクセサリーではなく、業務とAIが接続する“現場”の囲い込みである。NVIDIAの本質的な競争優位は、HopperやBlackwellのようなハードウェアにとどまらない。むしろ、Agentic AI時代を見据えたソフトウェア群と、それを導入・運用するエコシステム全体の構造設計にある。今回の決算説明とカンファレンスコールでは、これらが“事例付き”で語られたことで、NVIDIAの支配構造がGPU供給の域を超えて、AIファクトリーの中枢ロジックそのものに入り込んでいる現実が改めて裏づけられた格好である。
NVLinkとAIファクトリーのインフラ化──「オンプレAI時代」の再来
今回の決算説明およびカンファレンスコールでは、NVIDIAが提唱するAIファクトリー構想が、単なるメタファーではなく、具体的なインフラ構築案件として顧客に導入されつつある実態が明らかにされた。ここで鍵となるのが、インターコネクト(接続技術)を含めた、AIファクトリーの“完全なパッケージ供給”である。
NVLinkを中心とするフルスタック構成
- NVLink 第5世代:最大130TB/sの広帯域通信により、GPU同士の密結合だけでなく、CPU・ストレージとの高速接続も実現。
- NVLink Fusion:物理層・プロトコルを再設計し、AI推論向けに最適化された通信インフラ。EthernetやInfiniBandの課題を補完。
- Spectrum-X/Quantum-X:それぞれEthernet・InfiniBandベースのネットワークファブリックとして、ラック間・データセンター間接続に対応。
- シリコンフォトニクス技術の導入により、エネルギー効率・伝送効率も飛躍的に向上。
これらを一貫して供給できるのは、NVIDIAだけがサーバー、GPU、ネットワーク、ソフトウェアを垂直統合で設計・販売しているからである。
なぜ「NVIDIAだけが可能」なのか?
多くのクラウド事業者(AWS、Azureなど)もAIインフラを構築しているが、それらは自社サービス用に最適化された“閉じた構造”である。
- 例:AWSのTrainium/Inferentia、AzureのOrion設計などは原則として外販されず、自社クラウド内での使用が前提。
- 結果として、外部の企業・政府が同等スペックのAIファクトリーを構築したくても、部材や設計思想が手に入らないという“再現性の壁”が生じている。
この点で、NVIDIAは初めから「どこでも導入可能な構造パッケージ」としてAIファクトリーを設計している点が異質であり、それが同社が“AIインフラのTSMC”と呼ばれる所以である。
オンプレAIファクトリーと“ソブリンAI”ニーズの融合
そして今、AIファクトリーは再び“オンプレミス”の世界に回帰しつつある。理由は明確である:
- 国家主導のAI(ソブリンAI)では、セキュリティ・データ主権の観点から、クラウド利用に制限がある。
- また、金融・製造業などリアルタイム性と閉域制御が必要な分野でも、クラウドでは応答速度や可用性が足りない。
- 結果として、ラック単位やデータセンター単位での導入が可能なNVIDIAパッケージは、事実上の「AI専用設備」として政府・企業に求められている。
すでに、アブダビ、インド、サウジアラビア、フランスなどがNVIDIAによるオンプレAIファクトリーの導入を進めており、今後ますます「国家単位でのAI構築」が広がる見通しである。
地政学・政商的リスクと対応力──「覇者としての中立性」
今回の決算説明で最も示唆的だったのは、数値では測れないNVIDIAの立ち回り──すなわち世界の地政学的摩擦を“インフラ設計の分散”という論理で乗り越えようとする姿勢である。ジャンセンCEOの発言と具体的な展開から、NVIDIAの動きは単なる“ビジネスの多極化”ではなく、「構造的支配を維持しつつ、表層では中立を装う」という政商的なバランス戦略と解釈すべきである。
業界の“最終判断”──Toshiya Hariの転職
今回の決算発表カンファレンスコールでは、実に驚いことがあった。それは、元ゴールドマン・サックスの半導体トップアナリストであったToshiya Hari氏がNVIDIAに入社し、IRに居たことだ。つまりゴールドマン・サックスでの知見を活かして、転職していたということだ。これは、長年にわたり業界全体を見渡してきた知性が、「未来はここにある」と判断した“究極の票”である。彼が企業分析の立場から、実務執行の当事者へと転じたことは、NVIDIAが地政学的リスクを超越する位置にあると確信された結果と見るべきである。
ジャンセンCEOの「等距離外交」
ジャンセンCEOの地政学的バランス感覚は特筆に値する。バイデン政権下の輸出規制に“従いながら”、中国向けにカスタムH20を出荷。一方で、トランプ政権が返り咲く可能性も見据え、中東・台湾にAIファクトリーを分散展開。さらに今回の決算直後に発表された中国・上海での研究拠点設立も、その文脈に沿って読み解くべきだ。これは“親中”ではなく、「市場規模とAI人材供給の現実に即した設計・研究能力のローカライズ」という意味合いが強い。NVIDIAにとって重要なのは「どこが味方か敵か」ではなく、「どこにTokenを生産させ、流通させられるか」なのである。
Constellation構想と中東ソブリンAI──支配構造の分離
NVIDIAが台湾でのConstellation構想(AIサーバー製造の地理的集中)を強化しつつ、中東での国家主導AIファクトリー建設に踏み出した背景には、単一拠点依存のリスクを排し、同時に“供給支配”は手放さないという矛盾を成立させる“構造分離戦略”がある。
- 台湾=製造ハブ(製造の要)
- 中東=AI国家としてのインフラ投資先(販売の要)
- 米国・欧州=政策リスク下の政治的正当性確保(政治の要)
このように、「Token生成の供給チェーン」そのものを多極化し、いずれの勢力からも敵視されない立ち位置を構築している。
論点再掲
- 今の構造は「中華包囲網」ではなく、AIインフラを巡る“再編成と棲み分け”ではないか?
- ジャンセンCEOは「アメリカ企業の代表」ではなく、計算資源のインフラ設計者=文明装置の設計者として振る舞っているのではないか?
- NVIDIAは、TSMCとは異なり、物理的な製造だけでなく、構造そのものを設計して世界に展開している。
まとめとアウトプット
以上を踏まえれば、「中国リスク」や「米国の輸出規制による成長鈍化」といった市場の懸念は、“表層的な摩擦”に過ぎない。実態は、NVIDIAがインフラの支配者として、各国の主権的要請を逆手に取り、むしろ“分散的な覇権”を築きつつある構造そのものである。NVIDIAは、インフラ提供者としての“中立”を武器にしながら、AIという文明の回路図を描く者として、静かに支配構造の中枢に位置している。
まとめ
本当に“織り込み済み”なのか──エヌビディア決算を前に考えるべきこと
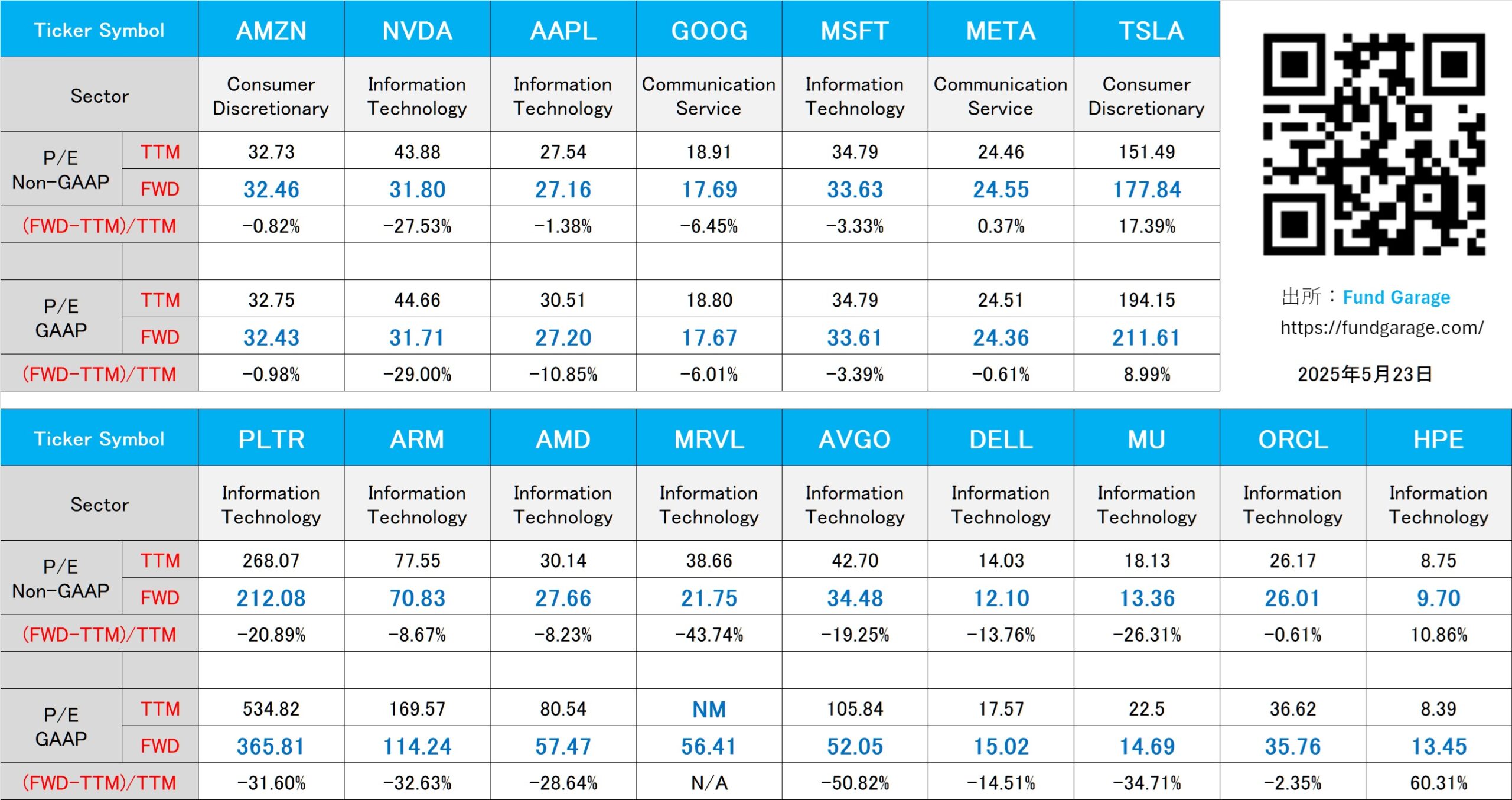
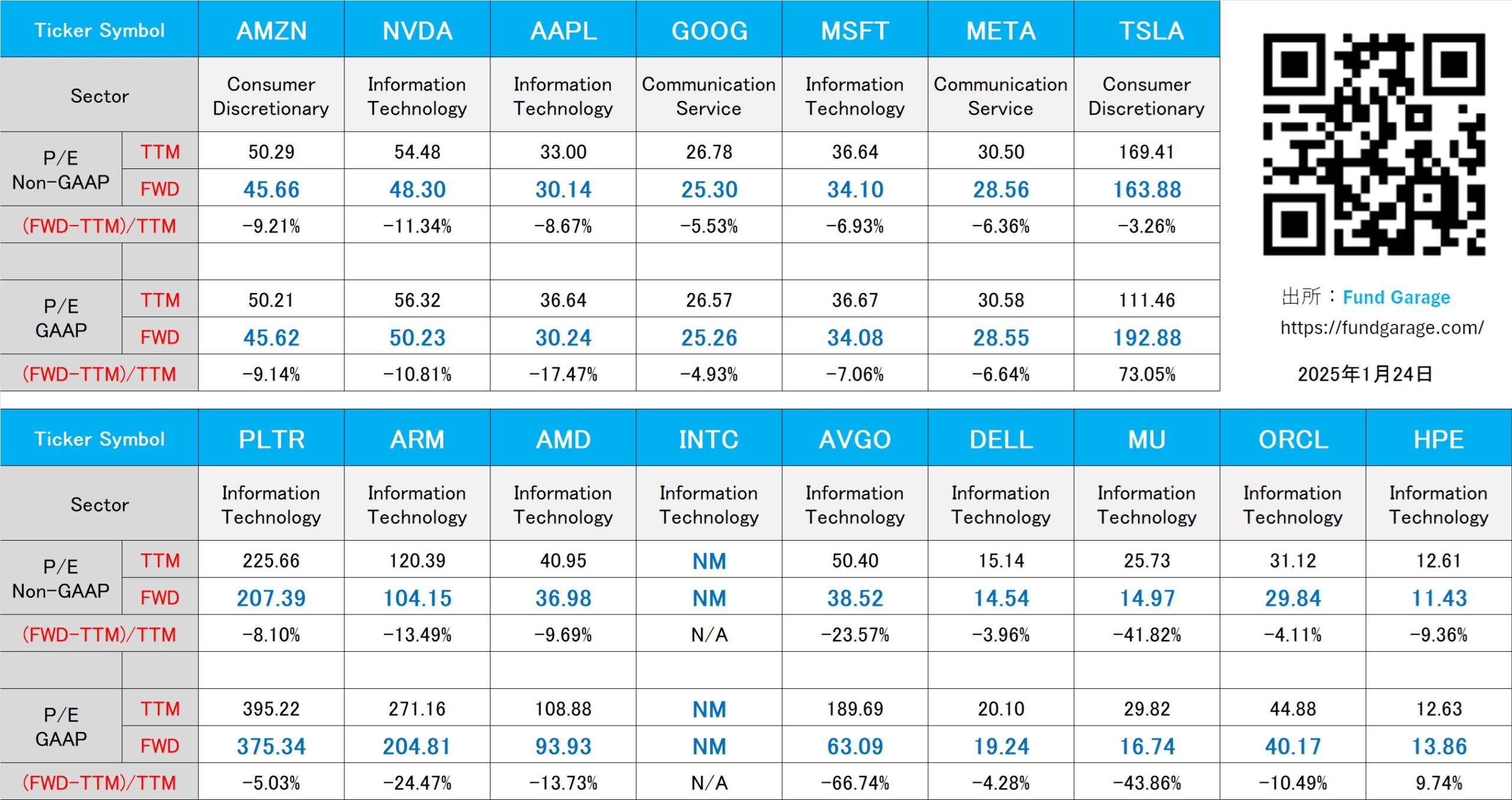
下記の表はいつもの米国株のPER(5月23日付)。